Some Maths Resources to Help You in Your ML Journey
I have been looking for content to improve my maths skills for ML. I have also noticed when scrolling a few threads many people did not find content that explains maths in an intuitive manner. Leading to a lack of belief in learning ML. But this does not have to be.
I’m with you, odd-looking characters and Greek letters don’t look welcoming. But they are some good teachers online that can demystify that experience.
Some of those materials are below:
3blue1brown Calculus and Linear Algebra series
I remember watching both of these series a while. And I will be watching them again. The narrator explores the topic without getting bogged down in the details. Feels like your discovering the maths with the original people who made calculus. In the linear algebra series, he does such a great job visualising vector space. You can see the various operations done to vectors and matrices in picture form.
3blue1brown Deep Learning series
Taking the concepts from the previous series and applying them to deep learning.
I’m sure you know about Sal Kahn by now. As you watched a couple of his videos. His video intuitively explains various topics. Also, show you the various hand by hand actions you need to take to do various calculations. Like matrix multiplication and calculating derivatives.
Mathematics for Machine Learning book
I tend to use this book as a reference guide if it’s a concept I want to check out. This book goes through the most important subjects relevant to machine learning and goes in-depth.
Mathematics for Machine Learning - Multivariate Calculus – Imperial College London
A multi-hour series explaining how calculus is used in deep learning. The material comes at the subject with a high-level view. But goes into sufficient enough detail to help you learn a lot.
Understand Calculus in 35 Minutes - The Organic Chemistry Tutor
A general overview of the subject. So you can be familiar with the concepts for deep learning later on.
NOTE: you won’t learn all of calculus in 30 minutes. But the video will help you get accustomed to the main ideas of the subject.
Now, these are resources that I have not used or have used very lightly but gotten good recommendations from various people.
So check them out:
This course talks about the linear algebra used in real computation. Not just Linear algebra done by hand.
Deep Learning book by Ian Goodfellow and Yoshua Bengio and Aaron Courville
From their website:
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular.
I have not thoroughly read all of the book. But I have used the notation page to understand maths symbols in various deep learning work.
An Introduction to Statistical Learning
A few people in this subreddit and the main subreddit have recommended this book. But I have never read it.
If you found this article interesting, then check out my mailing list. Where I write more stuff like this
Neural Networks you can try to implement from scratch (for beginners)
I was reading a tweet talking about how useful it is to implement neural networks from scratch. How it allowed for a greater understanding of the topic. The author said he found it more useful than other people explaining the concept to him.
While I disagree with the author’s opinion that it stops the need for explanations. It certainly does help the understanding of one’s model.
I recommend giving it a go. In the blog post, I will suggest which models you should try to implement from scratch using NumPy or your favourite library. Also, I will link to some accompanying resources.
Simple Feedforward Network
This is the most famous example because it’s so simple. But allows you to learn so much. I heard about this idea from Andrew Trask. It also helped me think about implementing networks from scratch in general.
In the Feedforward network, you will be using NumPy. As you won't need Pytorch or TensorFlow. To do the heavy-lifting for complex calculations.
You can simply create a Numpy Array for training and testing data. You can also create a nonlinear function using Numpy. Then work out the error rate between the layer’s guess and real data.
Resource for this task: https://iamtrask.github.io/2015/07/12/basic-python-network/
Follow this tutorial. It does a much better job of explaining how to do this in NumPy. With code examples to follow.
Feedforward Network with Gradient Descent
This is an extension of the network above. In this network, we allow the model to optimise its weights. This can also be done in NumPy.
Resource for this task: https://iamtrask.github.io/2015/07/27/python-network-part2/
A follow-on from the previous article.
Pytorch version of Perceptrons and Multi-layered Perceptrons.
Here will go up a level by using a library. Examples I'm using will be done in Pytorch. But you can use whatever library you prefer. When implementing these networks, you learn how much a library does the work for you.
Recourses for the task:
https://medium.com/@tomgrek/building-your-first-neural-net-from-scratch-with-pytorch-56b0e9c84d54
https://becominghuman.ai/pytorch-from-first-principles-part-ii-d37529c57a62
K Means Clustering
Yes, this does not count as a network. But a traditional machine learning algorithm is still very useful. As this is non deep learning algorithm it should be easier to understand. This can be done just using NumPy or Pandas depending on the implementation.
Recourse for this task:
https://www.machinelearningplus.com/predictive-modeling/k-means-clustering/
https://gdcoder.com/implementation-of-k-means-from-scratch-in-python-9-lines/
There are quite a few choices to choose from. So pick whatever implementation helps you understand the concepts better.
These networks or models should be simple enough that you won't get lost trying to implement them. But still, help learn a few stuff along the way.
-
If you found this post useful, then check out my mailing list where I write more stuff like this.
Tips For Learning ML If You Don't Like learning Via Courses
I read a Reddit post about how the OP was struggling to learn ML. Because he found the courses abstract and theoretical. And did not see how it would relate to his ML goals. In the people gave their opinions and useful suggestions.
Some of those suggestions I will be showing below:
Create A Side Project
Start working on a project that would involve ML. Then you can learn about the topic as you’re developing the project. You can write about what learned in a blog post, so you know what to work on next time.
Implement A Paper
Implementing a paper helps learn new concepts and forces you to translate that knowledge into a tangible item.
Take Courses That Focus On Coding Models Straight Away
I recommend FastAI which is a very hands-on course. Which focuses on working on ML examples straight away. This course helps you learn the basics of Deep Learning while of some tangible examples to show.
Tutorials Provided By PyTorch and Tensorflow
You can try the tutorials provided on their websites. You will work through practical examples on how to use the library. And you can read about the concepts that some tutorials talk about along the way.
Create Your Favourite Models From Scratch
This idea is from Andrew Trask. You create neural networks only using NumPy. This will force you to turn any theoretical knowledge you have about ML into real-life examples. It won’t be enough to name a concept and move on. But you will need to make tangible examples of the concepts. This can be done for your favourite libraries as well.
Additional note:
You still need theoretical knowledge if you want to do well with ML. As want to know how your model works behind the scenes. And it helps you grasp any new concept that comes your way. If you want to learn about maths. Check out these resources (MML book and YC Learning Math for Machine Learning). As maths is something that many people struggle with when learning ML.
After this, you should be more confident about learning ML. And have hands-on experience making models and a greater understanding of courses you were watching.
-
If you found this post useful, then check out my mailing list where I write more stuff like this.
Using assert statements to prevent errors in ML code
In my previous post, I showed what I learnt about unit testing. Testing tends not to be thought about when coding ML models. (The exception being production). So, I thought it will be an interesting topic to learn about.
I found one unit test to try out because it solves an issue. I face a lot when coding up my model.
The unit test checks if I’m passing the right shape of data into the model. Because I make this simple mistake from time to time. This mistake can add hours to your project. If you don’t know the source of the problem.
After I shared the blog post on Reddit. A Redditor commented. “Why not just use assert?”
That was something that did not cross my mind. So, I rejigged my memory, by checking out what assert did.
Then started working out how to use it for testing ML code.
One of the most popular blog posts on the internet about ML testing. Uses assertion statements to test the code.
When writing an assertion statement making a function is needed most of the time. This is how unit tests can be made.
Assertion Statement for the Wrong Shape
I was able to hack up this simple assertion statement.
def test_shape(): assert torch.Size((BATCH_SIZE, 3, 32, 32)) == images.shapeThis is even shorter than the unit test I created in the last blog post.
I tried out the new unit test. By dropping the batch size column. The same thing I did in the last post.
images = images[0,:,:,:]images.shapeNow we get an assertion error:

To make the assertion statement clearer. I added info about the shapes of the tensors.
def test_shape(): assert torch.Size((BATCH_SIZE, 3, 32, 32)) == images.shape, f'Wrong Shape: {images.shape} != {torch.Size((BATCH_SIZE, 3, 32, 32))}'
This is super short. Now, you have something to try out straight away for your current project.
As I spend more time on this. I should be writing about testing ML code.
An area I want to explore with ML testing is production. Because I can imagine testing will be very important to make sure the data is all set up and ready. Before the model goes into production. (I don’t have the experience, so I'm only guessing.)
When I start work on my side projects. I can implement more testing. On the model side. And the production side. Which would be a very useful skill to have.
-
If you liked this blog post. Consider signing up to my mailing list. Where I write more stuff like this
Stop passing the wrong shape into model with a unit test
When coding up a model. It can be easy to make a few trivial mistakes. Leading to serious errors when the training model later on. Leading to more time debugging your model. Only to find that your data was in the wrong shape. Or the layers were not configured properly.
Catching such mistakes earlier can make life so much easier.
I decided to do some googling around. And found out that you could use some testing libraries. To automatically catch those mistakes for you.
Now entering the wrong shape size through your layers. Should be a thing of the past.
Using unittest for your model
I’m going to use the standard unittest library. I used from this article: How to Trust Your Deep Learning Code.
All credit goes to him. Have a look at his blog post. For a great tutorial on unit testing deep learning code.
This test simply checks if your data is the same shape that you intend to fit into your model.
Trust me.
You don’t know how many times. An error pops up that is connected to this. Especially when you're half paying attention.
This test should take minutes to set up. And can save you hours in the future.
dataiter = iter(trainloader)images, labels = dataiter.next() class MyFirstTest(unittest.TestCase): def test_shape(self): self.assertEqual(torch.Size((4, 3, 32, 32)), images.shape)#This to run:
unittest.main(argv=[''], verbosity=2, exit=False) test_shape (__main__.MyFirstTest) ... ok ----------------------------------------------------------------------Ran 1 test in 0.056s OK<unittest.main.TestProgram at 0x7fb137fe3a20>
The batch number is hard-coded in. But this can be changed if we save our batch size into a separate variable.
The test with the wrong shape
Now let’s check out the test. When it has a different shape.
I’m just going to drop the batch dimension. This can be a mistake that could happen if you manipulated some of your tensors.
images = images[0,:,:,:]images.shape torch.Size([3, 32, 32]) unittest.main(argv=[''], verbosity=5, exit=False)
As we see, the unit test catches the error. This can save you time. As you won’t hit this issue later on when you start training.
I wanted to keep this one short. This is an area I’m still learning about. So I decided to share what I just learnt. And I wanted to have something you can try out straight away.
Visit these links.
These are far more detailed resources about unit testing for machine learning:
https://krokotsch.eu/cleancode/2020/08/11/Unit-Tests-for-Deep-Learning.html
https://towardsdatascience.com/pytest-for-data-scientists-2990319e55e6
https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765
https://towardsdatascience.com/unit-testing-for-data-scientists-dc5e0cd397fb
As I start to use unit testing more for my deep learning projects. I should be creating more blog posts. Of other short tests, you can write. To save you time and effort when debugging your model and data.
I used Pytorch for this. But can be done with most other frameworks. TensorFlow has its own test module. So if that’s your thing then you should check it out.
Other people also used pytest and other testing libraries. I wanted to keep things simple. But if you’re interested you can check out for yourself. And see how it can improve your tests.
…
If you liked this blog post. Consider signing up to my mailing list. Where I write more stuff like this
How to extract currency related info from text
I was scrolling through Reddit and a user asked how to extract currency-related text in news headlines.
This is the question:
Hi, I'm new to this group. I'm trying to extract currency related entities in news headlines. I also want to extend it to a web app to highlight the captured entities. For example the sentence "Company XYZ gained $100 million in revenue in Q2". I want to highlight [$100 million] in the headline. Which library can be used to achieve such outcomes? Also note since this is news headlines $ maybe replaced with USD, in that case I would like to highlight [USD 100 million].
While I did not do this before. I have experience scraping text from websites. And the problem looks simple enough that would likely require basic NLP.
So, did a few google searches and found many popular libraries that do just that.
Using spaCy to extract monetary information from text
In this blog post, I’m going to show you how to extract currency info text from data.
I’m going to take this headline I found from google:
23andMe Goes Public as $3.5 Billion Company With Branson Aid
Now by using a few lines of the NLP library of Spacy. We extract the currency related text.
The code was adapted from this stack overflow answer
import spacy nlp = spacy.load("en_core_web_sm")doc = nlp('23andMe Goes Public as $3.5 Billion Company With Branson Aid') extracted_text = [ent.text for ent in doc.ents if ent.label_ == 'MONEY']print(extracted_text) ['$3.5 Billion']
With only a few lines of code, we were able to extract the financial information.
You will need to have extra code when dealing with multiple headlines. Like storing them a list. And having a for loop doing the extraction of the text.
Spacy is a great library for getting things done with NLP. I don’t consider myself expert in NLP. But you should check it out.
The code is taking advantage of spaCy’s named entities.
From the docs:
A named entity is a “real-world object” that’s assigned a name – for example, a person, a country, a product or a book title. spaCy can recognize various types of named entities in a document, by asking the model for a prediction.
The named entities have annotations which we’re accessing with the code. By filtering the entities to have money type only. We make sure that we are extracting the financial information of the headline.
How to replace currency symbol with currency abbreviation.
As we can see Spacy did a great job extracting the wanted information. So we did the main task.
In the question, the person needed help with replacing the dollar sign with USD. And included highlighting the financial information.
The replacement of the dollar sign is easy. As this can be done with native python functions.
extracted_text[0].replace('$', 'USD ') USD 3.5 BillionNow we have replaced the symbol with the dollar abbreviation. This can be done with other currencies that you want.
Highlighting selected text in data
The highlighting of the text moves away from processing data. And more of the realm of web development.
The highlighting of the text. Would require adjusting the person’s web app. To have some extra HTML and CSS attributes.
While I don’t have the know-how to do that.
I can point you to some directions:
Highlight Searched text on a page with just Javascript
https://stackoverflow.com/questions/8644428/how-to-highlight-text-using-javascript
Hopefully, this blog post has helped your situation. And on your way into completing your project.
If you want more stuff like this. Then checkout my mailing list. Where I solve many of your problems straight from your inbox.
Can Auditable AI improve fairness in models?
Not unique but very useful
I was reading an article on Wired about the need for auditable AI. Which would be third party software evaluating bias in AI systems. While it sounded like a good idea. But I couldn’t help think it’s already been done before. With Google’s what if tool.
The author explained that the data can be tested. By checking how the AI responds by changing some of the variables. For example, if the AI judges if someone should get a loan. Then what the audit would do. Is check that does the race effect getting the loan. Or gender, etc. So if a person with the same income but different gender. Denied a loan. Then we know the AI harbours some bias.
But the author makes it sound that it’s very unique or never been done before. But Google’s ML tools already have something like this. So the creator of the AI can already audit the AI themselves.
But there is power by using a third party. That third party can publish a report publicly. And also won't be hiding data that is unfavourable to the AI. So a third party can keep the creator of the AI more accountable. Then doing the audit on your own.
Practically how will this work?
Third parties with auditable AI
We know that not all AI will need to be audited. Your cat vs dogs does not need to be audited.
The author said this will be for high stakes AI. Like medical decisions. Or justice and criminal. Hiring. Etc. This makes sense.
But for this to work seems like the companies will need to buy-in. For example, if an AI company decides to do an audit and find out their AI is seriously flawed. And no one wants their product because of it. Then companies are less likely to do so.
Maybe first the tech companies should have some type of industry regulator. That makes standards on how to audit AI. And goals for one to achieve. Government initiative will be nice. But I don’t know if the government has the know-how at the moment. To create regulation like this.
Auditing the AI. Will require domain knowledge.
The variables needed to change in the loan application. Is different for AI that decides if a patient should get medicine. The person or team doing the auditing. Will need to know what they are testing. The loan application AI can be audited for racism or sexism. The medicine AI can be audited for certain symptoms or previous diseases. But domain knowledge is highly needed.
For the medicine example. A doctor is very likely to part of the auditing team.
On the technical side, you may want to ask the creators to add extra code to make auditing easier. Like some type of API that sends results to the auditable AI. Creating an auditable AI for every separate project. Will get bogged down fast. Some type of formal standard will be needed to make life easier for the auditor and creator of the AI.
This auditable AI idea sounds a bit like pen testing in the cybersecurity world. As your stress testing (ethically) the systems. In this context we are stress testing how the AI makes a decision. Technically you can use this same idea. For testing adversarial attacks on the AI. But that is a separate issue entirely.
From there it may be possible to create a standard framework. On how one will test AI. But this depends on the domain of the AI. Like I said above. Because of that, it may not scale as well. Or likely the standards will need to be limited. So, it can cover most auditable AI situations.
Common questions for when auditing ones AI:
How to identify important features relating to the decision?
Which features could be classed as discrimination if a decision is based on them?
i.e. Gender, race, age
How to make sure the AI does not contain any hidden bias?
And so on.
It may be possible that auditable AI. Can be done by some type of industry board. So it can act as its regulator. So they can set their frameworks on how to craft auditable AI. With people with domain knowledge. And people who are designing the audited AI. To keep those ideas and metrics in mind. When developing the AI in the first place.
The audible AI by a third-party group. Could work as some type of oversight board. Or regulator. Before the important AI gets released to the public.
It is a good idea, to do regular audits on the AI. After the release. As new data would have been incorporated into the AI. Which may affect the fairness of the AI.
Auditable AI is good step, but not the only step
I think most of the value comes the new frameworks overseeing how we implement AI. In many important areas. Auditable AI is simply a tool. To help with that problem.
In some places, auditable AI tools will likely be internal. I can’t imagine the military opening up their AI tools. To the public. But it will be useful for the army that AI can make good decisions. Like working out what triggers a drone to label an object and enemy target.
Auditable AI may simply be a tool for debugging AI. Which is a great thing don’t get me wrong. Something that we all need. But may not be earth-shattering.
And what many people find out. About dealing with large corporations or bodies like governments. That they may drop your report. And continue what they were doing anyway. A company saying it opening its AI. For third party scrutiny is great. PR wise. But will they be willing to make the hard decisions? When the auditable AI tells you. Your AI has a major bias. And fixing that will cause a serious drop in revenue.
Will the company act?
Auditable AI is a great tool that we should develop and look into. But it will not solve all our ethical problems with AI.
Forecasting time series data with outliers, How I failed
How I got started
I was researching how to deal with outliers for time series data. And it led me to a big rabbit hole.
I noticed that there is a lot of material on how to detect outliers. (anomaly detection). But not much information out there to deal with them afterwards.
I want to detect the outliers for forecasting data. The idea is that you may want to deal with data. With heavy shocks. Think of airline industries after massive lockdowns.
For normal data. There is numerous information about dealing and removing outliers. Like values are in furthers ranges. Then you can remove them. Stuff like z-score etc.
When starting on the project. I want to use time-series data. Which I knew had a major shock. So I choose a dataset. of air passengers in Europe. Due to a major drop in demand in 2020. But while I used it before. I noticed that it was very difficult to select the data I want. So I eventually gave up.
That’s Failure 1
So I thought, I will try to create a fake dataset. That can act like time-series data. So I settled with a sine wave. As this data has a clear trend. (going up and down). Going across time. So I thought this should be an easy thing to forecast.
As I want to learn about the outliers. I manually edited them myself into the dataset.

Finding the outliers
So now work begins detecting the outliers. This took more longer than expected. As I was scrolling through a few blogs posts. Working out how to detect anomalies. I settled on this medium article. While the article was good. I struggled to adapt it to my project.
I noticed the first major roadblock holding me back. I was opting to use NumPy only. As this was used to produce the sine wave data. I thought I can use separate lists and plot them. This made life more difficult than it should be. Dealing with the different shapes of the arrays and whatnot. So I started to use pandas.
That’s Failure 2
Now started making more progress. As it was starting to more closely resemble the code from the tutorial.
For the anomaly detection, I used Isolation forest. As that was a popular technique I saw thrown around. For anomaly detection. And I haven’t used isolation forest before.
The idea was to try multiple techniques and compare them. But taking too much time. The tutorial had the option of isolation forest, so I did that.
There was a bit of an issue plotting the data with markers. But it eventually got solved. By adding a customisation for copying a dataset. For data visualisation.
While it was as able to spot outliers I added. It got a few false positives. I don’t know why.

After I was able to plot the outliers correctly. I decided to work on the forecasting model.
Forecasting the data
I got the code for the forecasting model here. It was not long before I had some issues.
First, I had to fix a minor issue. With outdated import code. By working the new function name. From the auto-suggest feature on Google Colab. I was able to fix it.
I ran into the issue of the data not being stationary. I thought that is something I could skip. With the cost of the model having lower results. But I was wrong. statsmodels could not fit the data. If the data was stationary.
So, I went back to the code as I was plotting the data. And starting work on differentiation. Luckily I already had experience doing this. Just had to get a refresher reading a blog post.
A major thing I noticed that a normal pandas difference did not make the data stationary. So I had to add customisations. Unexpectedly a double difference function. With the frequency set, 20 worked. The sine wave frequency was set at 5. But the same number did not turn the data stationary.
normal_series_diff = normal_df['value'].diff().diff(20).dropna()
After that, I was able to fit the data into the model.
Then I decided to forecast the model. Using the data I train on as a measure. Then statsmodels was giving me Convergence Warnings. And did not print the expected vs predicted values correctly.
Printing it like this:
predicted=-0.000000, expected=0.000000predicted=0.000000, expected=-0.000000
But I was still able to get the graph though:

While the RMSE was broken.
I decided to move on to forecasting the data with the outliers. I did the same thing as above. But this it gave no issues nor warnings.

Example:
predicted=-0.013133, expected=-4.000000
predicted=1.574975, expected=4.000000
As we can see the forecasting looks a bit odd.
A major thing I did not do was changing the model parameters. Nor did I do autocorrelation. To work that out. I wanted to move fast. But in hindsight that may have been wrong.
That’s failure number 4
Now I wanted to forecast the data. With the outliers removed.
This was the code to do that:
outliers_removed.drop(outliers_removed[outliers_removed['anomaly2'] == -1].index, inplace=True)And this is what it looked like:
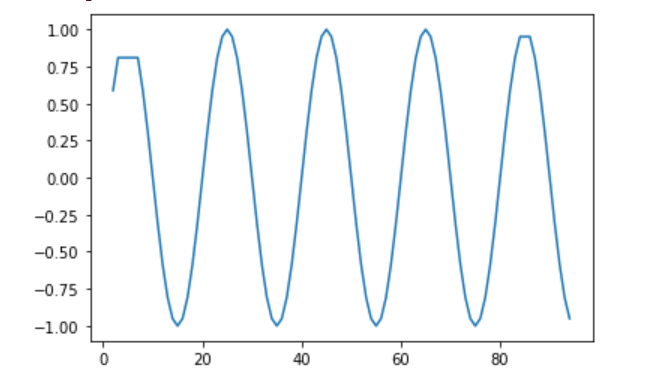
And I did differentiation with data. So make it stationary. Like I did earlier.
This is the result of the model:

Probably the best one.
With statsmodels printing out real values:
predicted=-0.061991, expected=-0.339266predicted=-0.236140, expected=0.339266predicted=-0.170159, expected=0.057537predicted=0.031753, expected=0.079192predicted=0.095567, expected=0.093096predicted=0.104848, expected=0.097887The aftermath
After all this. This raises more questions than answers. Why did the dataset with missing data? Do the best? While the normal data struggled to get forecasted.
What should one do with outliers in time series data?
Should you just remove it? Like I did. Or try to smooth it out somehow.
How should one create a fake dataset for time series? When I googled the question. People just use NumPy random function. Which I know works. For testing out a toy dataset.
But horrible for forecasting. Due to the lack of any patterns in the data.
I know this because I did a project which I used a randomly generated dataset. Used an RNN to forecast. Due struggled because the data was random.
If you want more failures like these 😛. Check out my mailing list
How to normalise columns separately or together
Normalization is a standard practice for machine learning. Helps improve results. By making sure your shares the same scale.
How should you normalise those features?
Should do them all at the same time?
Normalise the columns separately?
This a question you may face if your dataset has a lot of features.
So what should you do?
The reason why I’m writing this is because a reddit user asked this question.
Is it better to normalize all my data by the same factor or normalize each feature/column separately.
Example: I am doing a stock prediction model that takes in price and volume. A stock like Apple has millions of shares traded per day while the price is in the hundreds. So normalizing my entire dataset would still make the price values incredibly small compared to volume. Does that matter? Or should I normalize each column separately?
This is a valid question. And something you may be wondering as well.
In this redditors case. I will separate the columns separately. As I think the difference between the volume and price is too big. Can’t imagine having value with the difference between 1 million volumes and $40.
But in your case, it may not be needed. If the highest value in your dataset is around a hundred. And your lowest one is 10. Then I think that’s fine. And you can normalise the whole dataset.
They are other reasons why you want to normalise columns separately.
Maybe you don’t want to normalise all of your columns. Because one of your columns certain values are very important. Like one shot encoding. Where having two values is very important.
Maybe you can’t practically do so. Because a couple of columns are text data types.
To be fair, not normalising all of your dataset is not a big issue. If your dataset is normalised, then it may not matter if your values 0000.1. As the values can was be converted back after putting it through the model. But it may be more easier to normalize specific columns. Rather than whole dataset. As the values maybe easier to understand. And you don’t feel the other columns would suffer much if they are not normalized either.
Like most data science. The answer to all this is test and find out.
If you try normalizing separate columns. Then the whole dataset. See which results give you better results. Then run with that one.
Whatever your answer. I will show you to normalise between the different options.
How to normalize one column?
For this, we use the sklearn library. Using the pre-processing functions
This is where we use MinMaxScaler.
import pandas as pdfrom sklearn import preprocessingdata = {'nums': [5, 64, 11, 59, 58, 19, 52, -4, 46, 31, 17, 22, 92]}df = pd.DataFrame(data)x = df #save dataframe in new variable min_max_scaler = preprocessing.MinMaxScaler() # Create variable for min max scaler functionx_scaled = min_max_scaler.fit_transform(x) # transfrom the data to fit the functiondf = pd.DataFrame(x_scaled) # save the data into a dataframe

Result

Now your column is now normalized. You may want to rename the column to the original name. As doing this sometimes removes the column name.
Normalizing multiple columns
Now if you want to normalize many columns. Then you don’t need to do much extra. To do this you want to create a subset of columns. You want to normalise.
data = {'nums_1': [39,36,92,83,26,1,-5,45,67,27], 'nums_2': [57,73,86,17,56,2,59,46,-3,87], 'nums_3': [97,69,63,55,6,85,84,49,78,41]}df = pd.DataFrame(data) 
cols_to_norm = ['nums_2','nums_3']x = df[cols_to_norm] min_max_scaler = preprocessing.MinMaxScaler()x_scaled = min_max_scaler.fit_transform(x)df = pd.DataFrame(x_scaled)

You can merge the columns back into the original dataframe if you want to.
Normalising the whole dataset
This is the simplest one. And probably something you already do.
Similar to the normalisation of the first column. We just use the whole data frame instead.
x = dfmin_max_scaler = preprocessing.MinMaxScaler()x_scaled = min_max_scaler.fit_transform(x)df_normalized = pd.DataFrame(x_scaled)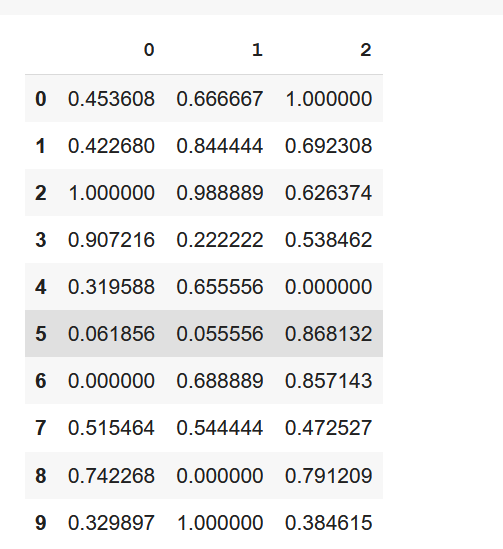
Now we have normalised a dataframe.
Now you can go on your merry way.
How to check if your model has a data problem
A couple of times you run your model. And the results are mediocre. While it may be a problem with the model itself. It may also be a problem with your data. If you suspect your model is underperforming because of data.
You can try a few things.
Do you have enough data?
Make sure you have enough data. This is yours to call. This will depend on what type of data you are dealing with. For example, images around 100 can be just enough. Before you add image augmentation. Tabular data, maybe a bit more.
Josh Brownlee mentions that:
The amount of data required for machine learning depends on many factors, such as:
The complexity of the problem, nominally the unknown underlying function that best relates your input variables to the output variable.
The complexity of the learning algorithm, nominally the algorithm used to inductively learn the unknown underlying mapping function from specific examples.
Do you have a balanced dataset?
Does your data consist of one main class? If so, you may want to change that. Having data like that skews the results one way. The model will struggle to learn about other classes. Adding more data from the other classes can help. If you have the issue above.
You could try under-sampling. Which means deleting data points from the majority class. On the flip side, you try can oversampling. Which means simply copying the minority class for more samples.
If your data has a few outliers, you may want to get rid of them. This can be done using Z-score or IQR.
Is your data actually good?
I’m talking about rookie mistakes like blank rows, missing numbers. Which can be fixed with a few pandas operations. Because they tend to be so small, they are easy to miss.
Assuming you are using pandas you can get rid of N/A. You can use the df.dropna().
Do you need some of the columns in your dataset? If not drop them. For example, if you are analysing house prices. Then data like the name of the resident is not a good factor for the analysis. Another example if you're analysing the weather of a certain area. Then dataset with 10 other areas is of no interest you.
To make life easier for yourself. If you are using pandas. Make sure the index is correct. To prevent headaches later on.
Check the data types of your columns. Because they may contain values of different data types. For example, if your column for DATE. Is a text data type. You may want to change that into a pandas date type. For later data manipulation.
Also, a couple of your values may have extra characters forcing them to be a different data type. For example, if one of your columns is a float data type. But one of the values looks like this [9.0??]. Then the value will count as a text data type. Giving you problems later on.
Features in your data
Your dataset may contain bad features. Features engineering will be needed to improve it.
You can start with feature selection. To extract the most useful features.
Do you have useless features like name and ID? If so remove them. That may help.
They are multiple techniques for feature selection. Like Univariate Selection, Recursive Feature Elimination, Principal Component Analysis.
Afterwards, you can try feature extraction. This is done by combining existing features into more useful ones. If you have domain knowledge then you can manually make your own features.
Do the feature scales make sense? For example, if one of your features is supposed to be in the 0 to 1 range. Then having a value that is 100. Means that it’s a mistake. That value will cause the data to skew one way. Due to it being an outlier.
Depending on your data. You can try one shot encoding. This is a great way to turn categorial data into numeric values. Which machine learning models like. You do this by splitting the categorical data into different columns. And a binary value is added to those columns.
Resources:
https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
https://machinelearningmastery.com/feature-extraction-on-tabular-data/
https://towardsdatascience.com/feature-extraction-techniques-d619b56e31be
https://machinelearningmastery.com/data-preparation-for-machine-learning-7-day-mini-course/