MyFitnessPal and OCR
This new project is the goal of coding up a python script to extract text from images. The images I want to extract are from is data from the MyFitnessPal app. If your familiar with the app you know that if you want to extract your data from the app to something like an csv file. Then you must pay extra money to do so. So, I thought this will be an interesting project to do.
So, when googling around I found a popular OCR python library used for extracting text from images. PyTesseract, the name in which the library is called. Is a python wrapper based on Google's Tesseract-OCR Engine. Which is a trained neural network which reads the text given to it. The python script will also be use the Pillow library to allow for the handing of image files in the program.
So first I made a new environment called OCR. To handle all of the packages involved in this project.

After that, I installed the needed packages for the project. Pillow and PyTesseract.


After then I noticed that I needed to install the Tesseract engine itself to my machine. Reading the introductions on the library’s wiki it suggested we should a install a windows installer from here.
After the installation I was set up. Using the code from this article. I made a simple function which should test the programs reading ability.
When I was trying to run the program, it gave me this error

When finished I added the tesseract OCR folder to windows PATH. But that still did not work. I found the solution was to create a variable called pytesseract.pytesseract.tesseract_cmd which will of the full path of the exe file. I noticed the exe file only appeared later on when I clicked some of the files. I don’t know why it did so, but it helped fix my issue.
Now after I ran the program after resolving the issues. It printed out this result

The example image used looked like this

A simple type up I made on Microsoft WordPad. So, it is fair to say that the experiment went well.
Now MyFitnessPal screenshots are from the android app. Because my phone allows for scrolling screenshots, I opted for that instead of multiple mini images.

As we can see the image is a wee bit long. But zooming in we can see the induvial values.

Looking at the screenshot at hand I think I will need to do a few crops. So the tesseract program does not confuse any images or symbols with text. I need to crop the top sections which contains the charts. Also, the right hand section of the values. As that were the images show. If there are not images on the value the app will show a symbol instead as we can see above.

I using paint 3d to crop the screenshot. The result now

As we can see this is plainer and less likely to cause hiccups in the OCR program.
Now running the program under this screenshot we get this result.

As we can see the program as able to understand the screenshot’s text almost perfectly. Now we want a way to export this. From looking at the manual of tesseract it allows for multiple output files. Mainly alto, hocr, pdf, tsv, txt. But I quickly found out that I only export pdf or hocr. Because the library I’m using to access the tesseract program, pytesseract allows exporting out data like boxes, page numbers etc. But not a clean export file like txt. So, I will have to code up the print statements of image_to_string function to an text file for further conversion. Mainly to an csv or tsv file for so it can be graphed and opened on any spreadsheet program like google sheets or excel.
Using this code from Quora I was able to find a solution. Which wrote down the values into a text file.

Now, converting the text file into a list is done so we can later convert it into a pandas dataframe. Using this line of code extracted the values in the file.
lineList = [line.strip('\n') for line in open('output.txt')]The list compression makes a new list by opening the output.txt file and extracting the lines in the file. The lines are also striped of to newline character as these are not needed.
When I printed the result, I noticed that the list kept empty strings.

So I had to make another list compression to remove the empty strings.
lineList = [x for x in lineList if x != '']After that needed a way to separate the values into there own rows. To do this I had to use list slicing. Something similar I used in my previous project.
res = [lineList[x:x+2] for x in range(0, len(lineList),2)]
Now the list is fully sorted. As each individual list is paired with their date and weight number.
The next step is convert into pandas. Which is not to hard as we did the work to sort out the data.
We want to make columns, so we make a list contains the names of them:
columns = ['Date', 'Weight']After that we can turn the list into a data frame and use the columns variable containing the names to set up the column of the dataframe.
df = pd.DataFrame(res, columns=columns)Which results in this:

We can say this is complete, I later noticed that the kg characters that are attached to the end of the strings. This will make it difficult for programs to analyse the data as is not numeric data.
So, choose to delete the “kg” characters. We can use the str.replace function.
df['Weight'] = df['Weight'].str.replace(r'kg', '')This code replaces the “kg” characters with an empty string in the Weight column.

Now final stage is to export the dataframe. This is simple, one line of code is needed:
df.to_csv('Weight_over_time.csv', index=False, encoding='utf-8')The df.to_csv is the function to export the dataframe to csv file.

This is how the csv looks in google sheets

As we can see the csv file formats very into the spreadsheet program.
This is graphing the data using the charts of google sheets.
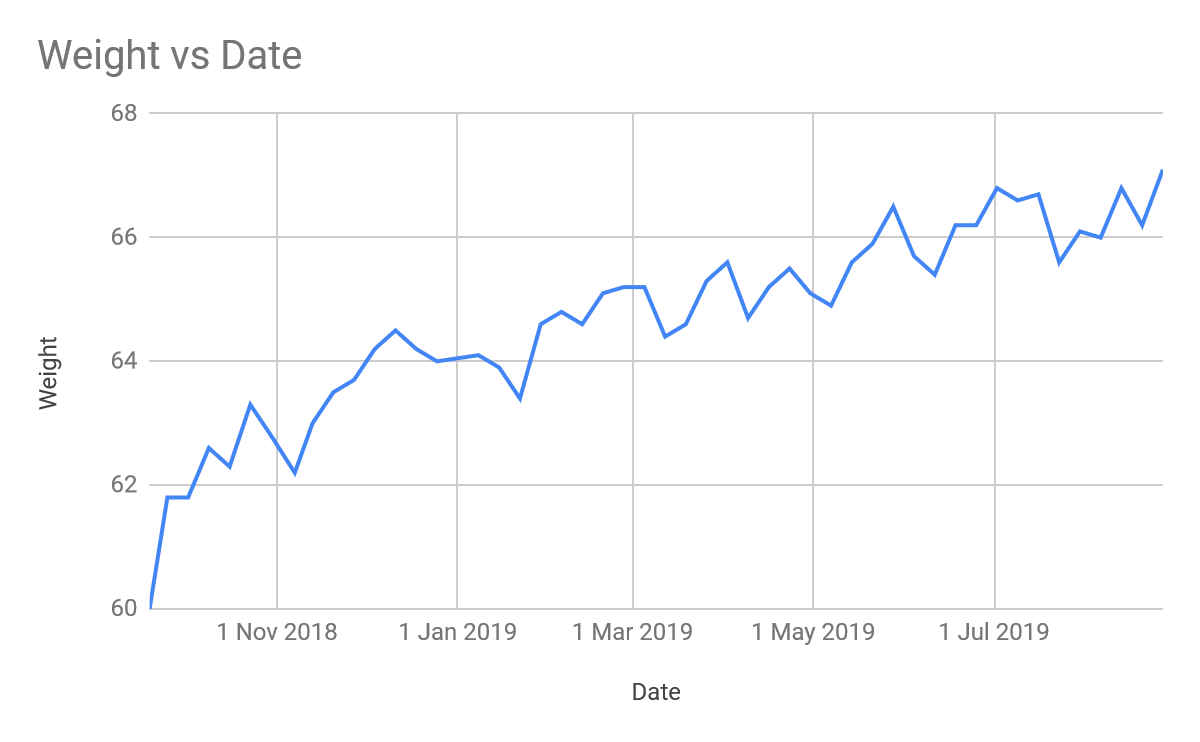
Now you know how convert screenshots from your phone to useful data using python.