Evernote scraper 7
Continuing from the previous article.
if re.search('---', values) or re.search('pra', values) or re.search('forgot', values):
lifts_writer.writerow(values_to_row)
print(values_to_row)
values_to_row.clear()
if re.search('Tick', values):
lifts_writer.writerow(values_to_row)
print(values_to_row)
values_to_row.clear()These if statements capture the out of order value and keep the loop of stopping.

Now we have all the data we just need to put the values in the right order again. This is because few of the values are in the wrong order.
The value where it talks about the tick system is a note. So it must be moved to the note column to the end. To do this simply create a simple for loop to inserst more none values into the columns. So the value will shift to the end.
for column in range(6):
values_to_row.insert(0, None)The value was pretty easy to sort out, but the problem now is mainly sort out the lifts so they are in the right column.
I tried sorting one lift out using this code:
if regex_bench.search(values_to_row[2]):
values_to_row.insert(2, 'TEST')
values_to_row.insert(3, 'TEST')But the problem is the position of the bench values changes so will not be correct all the time.
for line in values_to_row:
if regex_bench.search(line):
print('POSTION OF VALUE:')
IndexValue = values_to_row.index(line)
print(values_to_row.index(line))
values_to_row.insert(IndexValue + 1 'TEST')
values_to_row.insert(IndexValue - 1, 'TEST')So I tried this solution which will make it more generalised as the position is based on the index of the value. This did not place the value in the correct places but with a minor change to the insert function It was able to work
values_to_row.insert(IndexValue, 'TEST')
values_to_row.insert(IndexValue + 1, 'TEST')So next step was to do the other lifts.
elif regex_deadlift.search(line):
print('POSTION OF VALUE:')
IndexValue = values_to_row.index(line)
print(values_to_row.index(line))
values_to_row.insert(IndexValue - 1, 'TEST')
breakWas code for the deadlift. But even though some of the values were in the correct order. I notice this way of coding the solution to sort out the values will not work. As new values will be inserted into the row to previous position will be undone. As the values will be shifted again.
Trying to replace the values_to_row.append(values) in the if statements did not work. First try simply did not do anything. Secord time tried to make a loop which would shift values if the it did not match the regex.
elif regex_press.search(values):
# try:
# for value in values_to_row:
# if value != regex_press.search(values):
# values_to_row.insert(2, 'TEST')
# except IndexError as error:
# print(error)
# continueThe problem is that it got stuck in the loop so it did not move on to sort out the next values in the list. So I went to move back to the if len(values_to_row) > 3 if statement to add to the sorting code.
I was able to write some fairly successful code to sort out the bench values.
if regex_bench.search(values_to_row[2]):
values_to_row.insert(4, values_to_row[2])
values_to_row.pop(2)
values_to_row.insert(2, 'TEST')This if statement checks the bench value via regex then moves the bench to the 4th index position in the list. The next line removes the old bench value and position though the pop function. The next line adds a test sting as I placeholder. Original I wanted it to simply be a nonetype but the functions don’t work correctly when dealing with nonetypes, also when checking the csv file to make sure the changes are correct the ‘TEST’ string makes it more clearer to spot rather that a single comma.

Below this is the csv file imported to google sheets. As we can see the there is some structure. The main issues that come apparent is that information of the lifts need to added to the list column. Also stilling trying to fix this lone deadlift value. The value is part of the October 4th but as the ifs statements allows 4 values per row it removes the deadlift value. To be honest I may just manual place the value on the correct row instead of spending time coding up a solution which I’m already doing. Especially that this pattern only happen handful of times in the in the file.

Able to get some progress down to split the extra content of the lifts to notes column.
if regex_squat.search(values_to_row[1]) and not (regex_ticks.search(values_to_row[1])):
if len(values_to_row[1]) > 10:
values_to_row.insert(6, values_to_row[1][10:])This code checks the if the first value of the row is a squat via regex. The and statement checks if the values does not have any tick emojis. After those criteria are met the next if statement checks that the value is greater than 10 characters if so the string will be sliced by 10th characters to the last remaining character then inserted to the notes column.
The problem now is that the notes value are not inserting probably. Some values are being inserted into the power clean column. Ive been playing around with the index in the insert function to solve the issue but I have not found it.
After dealing with the code of above I decided to get rid of the 10: slice of the string. As I found that slicing the string into the notes section removed the context of the comment. So when reading you don’t not what lift the note is referring to.
Also to fix the issue of the values not inserting into the right colum I added more placeholder values so the value ends up in the correct place. The issue previously is that the value was placed as the last item in the row regardless of the index chosen. So if the row ends before the chosen index it will not placed correctly.
Have made more dupilates to extracts the lifts notes to the right column.
if regex_deadlift.search(values_to_row[3]) and not (regex_ticks.search(values_to_row[3])):
if len(values_to_row[3]) > 13:
values_to_row.insert(7, values_to_row[3])
else:
pass
try:
if regex_bench.search(values_to_row[4]) and not (regex_ticks.search(values_to_row[4])):
if len(values_to_row[4]) > 10:
values_to_row.insert(7, values_to_row[4])
else:
pass
except IndexError:
passThe second if statement is under a try/expect block, because the program stops under an index error as the bench value will not be under every row. The block allows the program to move on if it does not have a value to check.
The main issue now is trying to allows notes that ticks on them. As the if statements prevent that. And allowing notes on dates.
When checking the csv file they are exceptions were on some days did not have the correct lift order. Like below

This was fixed by extra if statements by inserting more placeholder statements
if values_to_row[0] == 'September 27:':
values_to_row.insert(4, 'TEST')
if values_to_row[0] == '21 April':
values_to_row.insert(3, values_to_row[2])
values_to_row.pop(2)
values_to_row.insert(2, 'TEST')
values_to_row.insert(4, values_to_row[3])
values_to_row.pop(3)
values_to_row.insert(3, 'TEST')The solution I’ve found to extract notes while values of the tick character is to attach .replace function next to the value called in the list.
if regex_squat.search(values_to_row[1]):
if len(values_to_row[1].replace('✔️', '')) > 14:
values_to_row.insert(7, values_to_row[1])
else:
pass
The replace function takes a away the ticks. While the len function can count the string without counting the tick emojis. This works as now all stings can be taken in regardless if they have ticks or not.
After that created a new python file to clean up the csv file. I didcied to opted to use the pandas library as it easier to deal with the indivual columns compared to the built-in csv library which deals with rows only.
I used the pandas str replace function to replace most of the unwanted charcters. Using the this list for unwanted items
regexfilter = ['[a-zA-Z]', '✔️', '❌', '➡️', '😕', ':', '\(.*\)', '✖️', '/']The first item selects all non-numeric characters. The next charcaters are emojis. The next ones the slash character.
df['Squat'] = df['Squat'].str.replace(r'|'.join(regexfilter), '')
df['Press'] = df['Press'].str.replace(r'|'.join(regexfilter), '')
df['Deadlift'] = df['Deadlift'].str.replace(r'|'.join(regexfilter), '')
df['Bench'] = df['Bench'].str.replace(r'|'.join(regexfilter), '')
df['Power clean'] = df['Power clean'].str.replace(r'|'.join(regexfilter), '')The next replacements are getting rid of the parentthises. This had to be done as the syntax does not allow you to select the parentheses characters normally as they count as regex special charcters.
This regex pattern selects the parentheses
df['Squat'] = df['Squat'].str.replace(r"\(.*\)", "")After that the final function is to use str.strip () which does the same job as the python strip(). So we can get rid of whitespaces.
df['Squat'] = df['Squat'].str.strip()Now this make the csv file easier to import into excel or google sheets

Custom edits will still have to be made though.
While edit I found a major error that few of lifts were in the wrong columns. Mainly few deadlifts where in the overhead press column.
While trying to find the solution for to move the correct column using the pandas library decided I’ve been spending to much time with this problem and I want to move on.
To manually the issue I when on google sheets and search on values that do not contain the characters for press. So I ended up with this set ^((?!pr|Pr).)*$
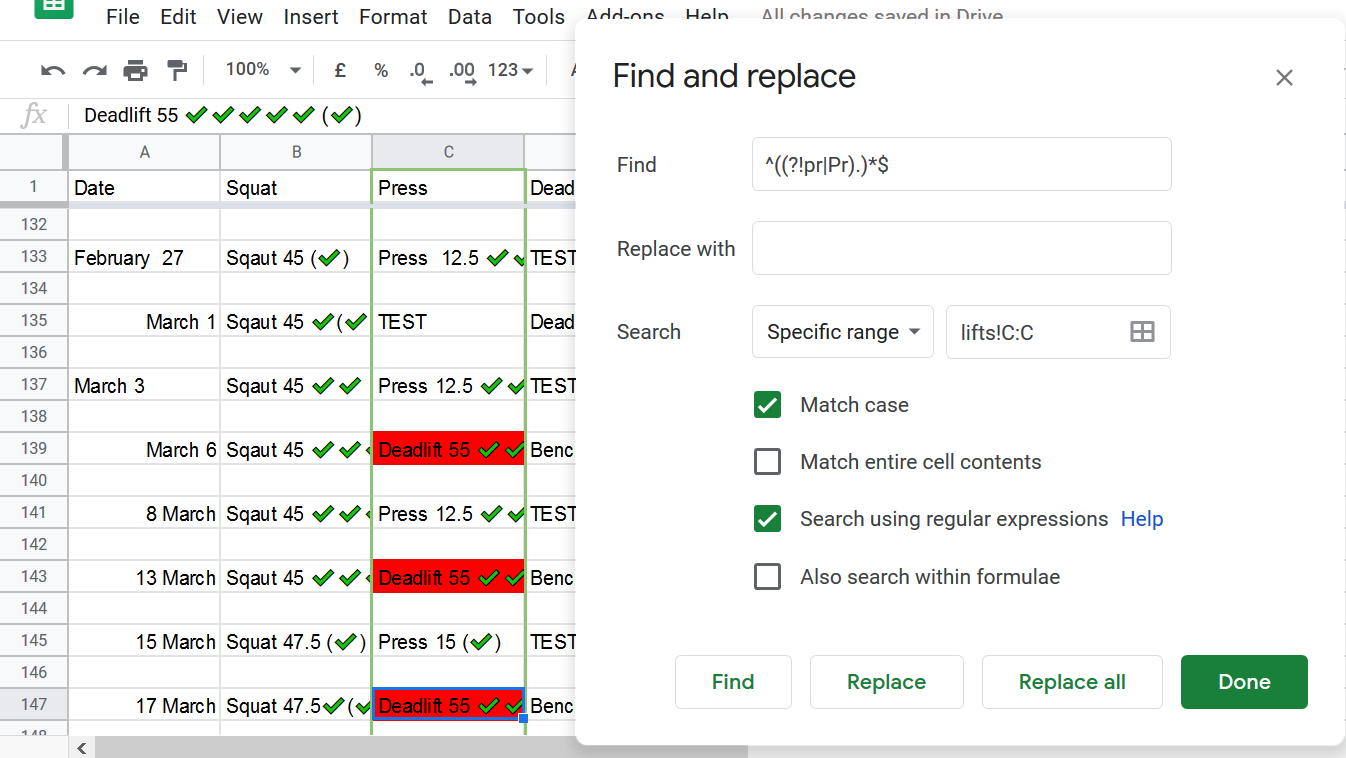
After I found them I highlighted them red so I can come bad to those rows to edit them.