How to avoid shiny object syndrome
If you’re a programmer who has suffered from this issue before. This set of events may happen to way too often. You are working on a project. Then just found out on Reddit. There is an interesting library that you can check out. Then you spend your whole day reading up on documentation. And trying out the library. But by the end of the day. You noticed that your original project. Has made little progress.
If that’s you.
You suffer from shiny object syndrome.
This blog post should be the antidote.
Why is shiny object syndrome dangerous?
You probably know why. You spend time running around in circles. Trying the next best thing. While you have little to show for it.
Shiny object syndrome reduces progress on many of your projects. Because of the time being spend switching between various projects. And starting them from scratch.
Imagine constructing a building which you only decide halfway to stop and make another one. Therefore, you need to disassemble and move your equipment. To the next construction zone.
All the time and effort could have been spent making even more progress with the original building.
We forget when starting a new project. That we need to spend time transitioning into the next project. That means researching how to start the next project. Refreshing your workspace for the next project. If your new project is not similar to your original project. Then you may have to learn new skills associated with the following project.
For example, if you’re a web developer then you decide to work on a blockchain project. Most likely, you need to spend time learning the ins and outs of blockchain technology. Which will take a lot of time.
Because of this, there is a lot of risks. Jumping from one project to another.
If you want to avoid this fate. Then I can recommend you some courses of actions below.
How to stop shiny object syndrome?
Wait a minute and breath.
Many times you start a project. After reading a great blog of some person’s project. And you think to yourself “I want to do that!”. Then you start googling around. Of the resources that the author used. Getting ready for a new awesome project.
Don’t get me wrong. Getting excited is a great emotion. But leads you spinning your wheels sometimes.
Instead of instantly creating a project based on your excitement. I would recommend writing your ideas down in a notebook. Ideally an online one like Evernote. So, you always have access to it.
This helps you get back to the task at hand. Then checking the idea when some time passes. Removes the euphoria of the moment. So, you can see your idea with rational eyes. And you may notice that idea was not that good in the first place. From there you avoided wasted time on a project. That would have been a dead end.
If you still think the idea is still good. Then start adding more details and plans.
Timebox space to explore new ideas
New technologies are awesome. Which may be part of the reason you’re in the community in the first place. But learning about new technologies take a lot of time. So what you may want to do is set aside time during your day or week. To explore the technology, you're most passionate about. This may help you explore your interests. Without your main task for the week or day. Being derailed. And this exploring can help think about your next project. When you are ready.
Have a plan to ship #BuildInpublic
Making sure you have a deliverable is a great way to have accountability. Having something like this will make you more likely to stay the course. If you want to do this on hard mode. Make it a public statement. So everybody can expect a product to be shipped. You are WAY less likely to abandon ship if people are expecting a product from you.
Once you start getting feedback from an audience. You may get an extra spike of motivation. To keep ongoing.
A term you should do more research on is Learn in public. (Interchangeably called build in public) This is where you share information about your project start to finish. The reason why this is good. Other than the reason above. That it will help you get more eyeballs on your project. Giving it more chance of succeeding. The feedback from the public should help make the project better. As now you have other people giving you ways to improve. Learning in public can help your next project. If your project is interesting, then they may stick around to see what you have in store.
Does the shiny object match your goals?
Maybe you have a general direction. Where you want some of your projects to go. If that’s the case you can ask. Does the shiny object achieve my goals? Or you can ask will this new technology help me do my job better. Do you think the new project will reduce the amount of time you need to work? Or can you get more work done in the same amount of time?
Asking precisely “How will this help me?” Should help you avoid. Going into a cul-de-sac.
Conclusion
Now I have given you a few ways to battle shiny object syndrome. And now you can finish your project through and through. Without jumping onto the next project that peaks your interests.
How to normalise columns separately or together
Normalization is a standard practice for machine learning. Helps improve results. By making sure your shares the same scale.
How should you normalise those features?
Should do them all at the same time?
Normalise the columns separately?
This a question you may face if your dataset has a lot of features.
So what should you do?
The reason why I’m writing this is because a reddit user asked this question.
Is it better to normalize all my data by the same factor or normalize each feature/column separately.
Example: I am doing a stock prediction model that takes in price and volume. A stock like Apple has millions of shares traded per day while the price is in the hundreds. So normalizing my entire dataset would still make the price values incredibly small compared to volume. Does that matter? Or should I normalize each column separately?
This is a valid question. And something you may be wondering as well.
In this redditors case. I will separate the columns separately. As I think the difference between the volume and price is too big. Can’t imagine having value with the difference between 1 million volumes and $40.
But in your case, it may not be needed. If the highest value in your dataset is around a hundred. And your lowest one is 10. Then I think that’s fine. And you can normalise the whole dataset.
They are other reasons why you want to normalise columns separately.
Maybe you don’t want to normalise all of your columns. Because one of your columns certain values are very important. Like one shot encoding. Where having two values is very important.
Maybe you can’t practically do so. Because a couple of columns are text data types.
To be fair, not normalising all of your dataset is not a big issue. If your dataset is normalised, then it may not matter if your values 0000.1. As the values can was be converted back after putting it through the model. But it may be more easier to normalize specific columns. Rather than whole dataset. As the values maybe easier to understand. And you don’t feel the other columns would suffer much if they are not normalized either.
Like most data science. The answer to all this is test and find out.
If you try normalizing separate columns. Then the whole dataset. See which results give you better results. Then run with that one.
Whatever your answer. I will show you to normalise between the different options.
How to normalize one column?
For this, we use the sklearn library. Using the pre-processing functions
This is where we use MinMaxScaler.
import pandas as pdfrom sklearn import preprocessingdata = {'nums': [5, 64, 11, 59, 58, 19, 52, -4, 46, 31, 17, 22, 92]}df = pd.DataFrame(data)x = df #save dataframe in new variable min_max_scaler = preprocessing.MinMaxScaler() # Create variable for min max scaler functionx_scaled = min_max_scaler.fit_transform(x) # transfrom the data to fit the functiondf = pd.DataFrame(x_scaled) # save the data into a dataframe

Result

Now your column is now normalized. You may want to rename the column to the original name. As doing this sometimes removes the column name.
Normalizing multiple columns
Now if you want to normalize many columns. Then you don’t need to do much extra. To do this you want to create a subset of columns. You want to normalise.
data = {'nums_1': [39,36,92,83,26,1,-5,45,67,27], 'nums_2': [57,73,86,17,56,2,59,46,-3,87], 'nums_3': [97,69,63,55,6,85,84,49,78,41]}df = pd.DataFrame(data) 
cols_to_norm = ['nums_2','nums_3']x = df[cols_to_norm] min_max_scaler = preprocessing.MinMaxScaler()x_scaled = min_max_scaler.fit_transform(x)df = pd.DataFrame(x_scaled)

You can merge the columns back into the original dataframe if you want to.
Normalising the whole dataset
This is the simplest one. And probably something you already do.
Similar to the normalisation of the first column. We just use the whole data frame instead.
x = dfmin_max_scaler = preprocessing.MinMaxScaler()x_scaled = min_max_scaler.fit_transform(x)df_normalized = pd.DataFrame(x_scaled)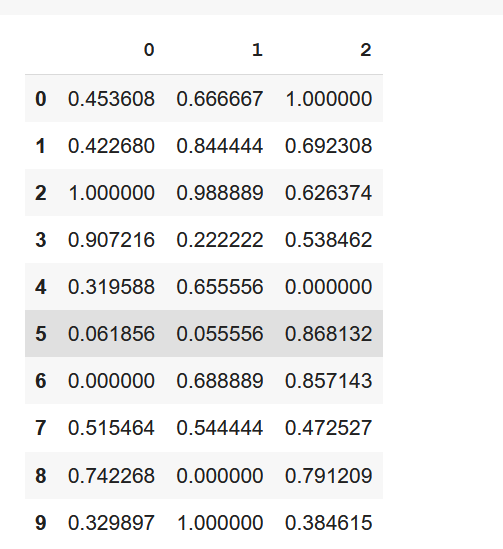
Now we have normalised a dataframe.
Now you can go on your merry way.
How to check if your model has a data problem
A couple of times you run your model. And the results are mediocre. While it may be a problem with the model itself. It may also be a problem with your data. If you suspect your model is underperforming because of data.
You can try a few things.
Do you have enough data?
Make sure you have enough data. This is yours to call. This will depend on what type of data you are dealing with. For example, images around 100 can be just enough. Before you add image augmentation. Tabular data, maybe a bit more.
Josh Brownlee mentions that:
The amount of data required for machine learning depends on many factors, such as:
The complexity of the problem, nominally the unknown underlying function that best relates your input variables to the output variable.
The complexity of the learning algorithm, nominally the algorithm used to inductively learn the unknown underlying mapping function from specific examples.
Do you have a balanced dataset?
Does your data consist of one main class? If so, you may want to change that. Having data like that skews the results one way. The model will struggle to learn about other classes. Adding more data from the other classes can help. If you have the issue above.
You could try under-sampling. Which means deleting data points from the majority class. On the flip side, you try can oversampling. Which means simply copying the minority class for more samples.
If your data has a few outliers, you may want to get rid of them. This can be done using Z-score or IQR.
Is your data actually good?
I’m talking about rookie mistakes like blank rows, missing numbers. Which can be fixed with a few pandas operations. Because they tend to be so small, they are easy to miss.
Assuming you are using pandas you can get rid of N/A. You can use the df.dropna().
Do you need some of the columns in your dataset? If not drop them. For example, if you are analysing house prices. Then data like the name of the resident is not a good factor for the analysis. Another example if you're analysing the weather of a certain area. Then dataset with 10 other areas is of no interest you.
To make life easier for yourself. If you are using pandas. Make sure the index is correct. To prevent headaches later on.
Check the data types of your columns. Because they may contain values of different data types. For example, if your column for DATE. Is a text data type. You may want to change that into a pandas date type. For later data manipulation.
Also, a couple of your values may have extra characters forcing them to be a different data type. For example, if one of your columns is a float data type. But one of the values looks like this [9.0??]. Then the value will count as a text data type. Giving you problems later on.
Features in your data
Your dataset may contain bad features. Features engineering will be needed to improve it.
You can start with feature selection. To extract the most useful features.
Do you have useless features like name and ID? If so remove them. That may help.
They are multiple techniques for feature selection. Like Univariate Selection, Recursive Feature Elimination, Principal Component Analysis.
Afterwards, you can try feature extraction. This is done by combining existing features into more useful ones. If you have domain knowledge then you can manually make your own features.
Do the feature scales make sense? For example, if one of your features is supposed to be in the 0 to 1 range. Then having a value that is 100. Means that it’s a mistake. That value will cause the data to skew one way. Due to it being an outlier.
Depending on your data. You can try one shot encoding. This is a great way to turn categorial data into numeric values. Which machine learning models like. You do this by splitting the categorical data into different columns. And a binary value is added to those columns.
Resources:
https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
https://machinelearningmastery.com/feature-extraction-on-tabular-data/
https://towardsdatascience.com/feature-extraction-techniques-d619b56e31be
https://machinelearningmastery.com/data-preparation-for-machine-learning-7-day-mini-course/
How to convert non-stationary data into stationary for ARIMA model with python
If you’re dealing with any time series data. Then you may have heard of ARIMA. It may be the model you are trying to use right now to forecast your data. To use ARIMA (so any other forecasting model) you need to use stationary data.
What is non-stationary data?
Non-stationary simply means that your data has seasonal and trends effects. Which change the mean and variance. Which will affect the forecasting of the model. As consistency is important when using models. If the data has trends or seasonal effects then the data is less consistent. Which will affect the accuracy of the model.
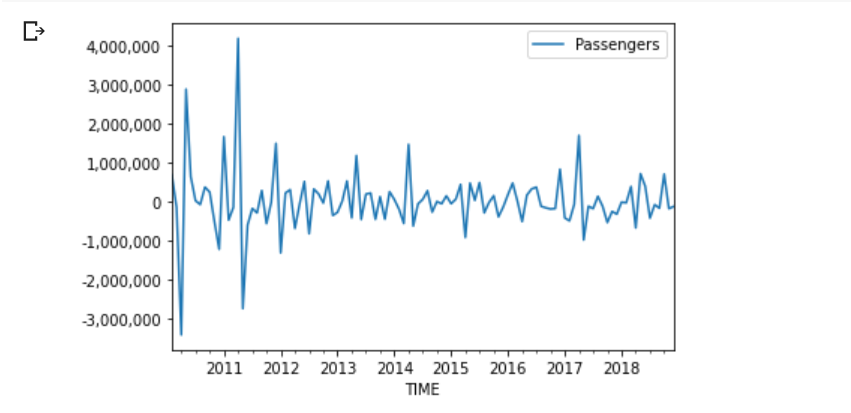
Example dataset
Here is an example of some time series data:

This is the number of air passengers each month. In the United Kingdom. You can fetch the data here. From 2009 to 2019.
As we can see the data has strong seasonality. As people start to go on their summer holidays. And a tiny bump in the winter. To avoid the cold. If you like to use a forecasting model, then you need to change this into stationary data.
Differencing
Differencing is a popular method used to get rid of seasonality and trends. This is done by subtracting the current observation with the previous observation.
Assuming you are using pandas:
df_diff = df.diff().diff(12).dropna()This short line should do the job. Just make sure that your date is the index. If not you will get a few issues plotting the graph.
If you still want to keep your traditional index then simply create a new dataframe. Keeping the columns separated and shifting your numerical column.
diff_v2 = df['Passengers'].diff().diff(12).dropna()time_series = df['TIME']
df_diff_v2 = pd.concat([time_series, diff_v2], axis=1).reset_index().dropna()The concatenation produces NaN values. As the passengers series is shifted ahead compared to the time series. We use the dropna() function. To drop those rows.
df_diff_v2 = df_diff_v2.drop(columns=['index'])
ax = df_diff_v2.plot(x='TIME')ax.yaxis.set_major_formatter(mpl.ticker.StrMethodFormatter('{x:,.0f}'))This is here as we are dealing with large tick values. This is not need if your values are less than thousand.
Now your data can be used for your ARIMA model.
If you found this tutorial helpful, then. Check out the rest of the website. And sign up to my mailing list. To get more blog posts like this. And short essays relating to technology.
Resources:
https://www.quora.com/What-are-stationary-and-non-stationary-series
https://www.analyticsvidhya.com/blog/2018/09/non-stationary-time-series-python/
https://machinelearningmastery.com/remove-trends-seasonality-difference-transform-python/
https://towardsdatascience.com/hands-on-time-series-forecasting-with-python-d4cdcabf8aac
Improve accuracy when adding new data to machine learning model
ML model having recall of .97 and precision of 93 and accuracy of 95 on test data but in completely new data it doesn't give good results. What could be the possible reason? – From Reddit
I have seen this too many times. Your model looks perfect with high scores. And somewhat low inference time. But you add new data to test how it would fair. But the results a negligible at best. So you start to wonder what’s wrong with my model. Or maybe it’s my data.
This is a case of overfitting. When the model overly learns the data from its training phase.
To fix this. You want to make sure your data is set up correctly. So make your dataset split into testing data and training data. And depending on your preference add a validation set as well.
Now start training your model using the training data. Which should learn enough to develop a general pattern of the data.
Now check using test data. If your test data is good, then half of the problem is solved. You then want to use the validation dataset to help tune your hyperparameters.
If the new data is giving poor results. Then you may want to find any mistakes in the model or data.
First things first. Simplify your model. Find the simplest model that can deal with your problem.
Second, turn off any extra features like batch normalization or dropout
Third, verify your input data is correct
On a separate note. Make sure your new data you're adding to model is correct as well. Sometimes we can do minor mistakes like forgetting to do pre-processing correctly when using a separate piece of data.
Doing this should remove any bits of your model that are adversely affecting your results. Checking the input data and the test data. Is a simple double-check. As an error in the data can go unnoticed. And maybe affecting your model. Doing this gives you are a chance to spot any of those errors.
Hopefully by doing many of the steps above. The issue should be fixed. If not go to the article I linked above. And go through all the steps in that article.
How to find similar words in your excel table or database
I was reading a post about a person who has a problem mapping data from an excel table to the database. You maybe find it tedious to transfer data between the “cats” fields to the “cat” field.
While I'm not an expert in NLP at all. From googling around it can somewhat be done.
First, you want to move your words you have into a separate text file.
If you have past data put them into two separate files. For original data and destination data.
For example:
original data: mDepthTo
destination data: Depth_To
For pre-processing. After that, you want to remove ASCII or miscellaneous characters. And punctuation. So, you want to get rid of a couple of those underscores. To make life easier for yourself turn the data into a uniform case. The NLTK library is good at this.
Then after that, you want to encode those words into vectors. Try TF-IDF. Again, you can use it with SK-learn. So, you don’t need to install any extra modules.
A brief explanation of TF-IDF
TF-IDF is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. This is done by multiplying two metrics: how many times a word appears in a document, and the inverse document frequency of the word across a set of documents https://monkeylearn.com/blog/what-is-tf-idf/
Now we want to work out the similarity between the vectors. You can use concise similarity as that’s the most common technique. Again, sklearn has this so you can try to out easily.
Cosine similarity is a metric used to measure how similar the documents are irrespective of their size. Mathematically, it measures the cosine of the angle between two vectors projected in a multi-dimensional space.
Now we make some progress on word similarity. As you can compare both words in your text files.
For testing, you may want to save some examples. So, you can use for evaluation of the NLP model. Maybe you can create a custom metric for yourself about how closely the model was able to match the destination data.
Most of the ideas came from this medium article. Just tried to adapt it to your problem
You should check it out. They know what they are talking about when it comes to NLP.
Summary:
1. Save data into separate text files
2. Pre-process the data. (Punctuation, odd characters etc)
3. Encode data with TF-IDF
4. Get word similarity with Cosine similarity
5. Create metric to use. To see if the model maps data correctly.