Coloring the Past: Using AI to Colorize Historical Images - Image Colorisation 101
Intro - The Art and Science of Bringing Color to the Past
Remember the old Kodak and Victorian images, the first commerical color photos and film came with Kodachrome during the late 1930s. But what if we could breathe life into those monochrome memories? Welcome to the world of image colorization - a blend of art, science, and cutting-edge technology that's revolutionizing how we view history.
This is a blog post giving your a rundown image colorization space using deep learning.
Why am I doing this?
My final year undergraduate project was about this topic. I think it's only right to share this knowledge in an understandable post instead of being locked behind a wall of academic wording. (Who doesn't like to read 10k PDF full of jargon?!??)
If you can see from my other work, this is not the first time of me doing an image colourization project. You can use an old Richard Feynman colorization with DeOldify breakdown. See here During my undergrad, my supervisor recommended me to continue working on the topic due to previous experience.
Whether you're a deep learning enthusiast, a history buff, or simply curious about how those viral "colorized history" posts are created, this post aims to provide you with a comprehensive understanding of image colorization. Strap in, and let's go.
What is Image Colourisation?
Now, what is image colourisation? While it's pretty simple, turning greyscale images into colour.
So the next logical question is, what's behind the VooDo magic that allows this to happen?
The power of deep learning, CNNs (Convolutional neural networks) to be precise.
CNN allows us models to "See" what's in the image.
Now what does image colourisation do turn those pixels into colour?
via comparing black and white images, with colors and features it as already seen before. It can start map greyscale pixels onto color. With the help of some smart color engineering should I say!
This whole basis of image colourisation.
The greyscale images are input output is the RGB layers. Also author metaphor is greyscale is the images and the layers of neural network is the RGB layers with output coloured images. Neural networks great for understanding non linear patterns. So tuning the right RGB combination for the target pixel is great for deep learning.
- Quick aside: A non-linear is simply a pattern that does not have 1:1 relationship. But there is still a relationship.

Decoding Color: Understanding RGB and LAB Color Spaces
But RGB is not the only color space used. LAB is used as well. Due to it being an absolute color space, color defined regardless of the device. And the separation of Lightness (brightness) vs color channels make it more precise when mapping the colors.
CIELAB color space - Wikipedia
I've used Claude to help provide an ELI5 explanation:
Imagine you have a big box of crayons. Some crayons are different shades of the same color, like light blue and dark blue. In the RGB color box, these crayons might be mixed up and hard to find. But in the LAB color box, they're organized in a special way:
The L drawer: This has all the light and dark versions of colors. It's like controlling how much sunlight shines on your drawing.
The A drawer: This has crayons going from green to red.
The B drawer: This has crayons going from blue to yellow.
When computer artists want to color a black-and-white picture, the LAB box makes it easier. They can choose how bright or dark to make things without messing up the colors. And they can pick colors that look good together more easily because the crayons are sorted in a way that makes sense to our eyes.
The LAB box also has some magic crayons that can make colors your regular crayon box can't! This lets artists make really pretty and natural-looking colorful pictures from black-and-white ones.
So, while RGB is like a regular crayon box, LAB is like a super-organized, magical crayon box that helps artists color pictures in a way that looks great to our eyes!

Convolutional Neural Networks in Image Colorization
On a high level, takes an image as input in the form of matrix of pixel. Then features (Lines, Texture shapes) are identified. As go though each layer its able to identify for complex shapes. (Dogs, Cats, legs etc). For the final layer used for classification.
Foe the features to be identified we use filters, a small matrices of weights that goes though the image. This down in a sliding window manner. starting from top left and though each section of the image one by one.


This is some short python code we can break down, that converts RGB to LAB.
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]We know that RGB has 3 channels. This is passed into the sklearn rgb2lab function.
Now the shape of image looks like this [insert image here].
Now we select the greyscale layer by selecting index zero. (The last element here is channel section, other elements is the pixels themselves). Calling [:,:,1:] selects channels A and B. green-red and blue-yellow.
Image of RGB image showing the channels in 3D space.

Channels are L A B. And row and column are images dims. 3D space remember.
After converting the color space using the function rgb2lab(), we select the greyscale (Lightness) layer with [:,:,0]. This is typically used as input for the neural network. [:,:,1:] selects the two color layers: A (green–red) and B (blue–yellow).



I'm not the best artist, so there other diagram and the videos above will be helpful as well.
skimage.color — skimage 0.23.2 documentation (scikit-image.org)
Here's a code snippet that would show how LAB channels are accessed.
import numpy as np
from skimage import color
import matplotlib.pyplot as plt
# Assume 'image' is your RGB image
lab_image = color.rgb2lab(image / 255.0) # Normalize RGB values to [0, 1]
L = lab_image[:,:,0] # Lightness channel (grayscale)
A = lab_image[:,:,1] # A channel (green-red)
B = lab_image[:,:,2] # B channel (blue-yellow)
# Visualize
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
axes[0,0].imshow(image)
axes[0,0].set_title('Original RGB')
axes[0,1].imshow(L, cmap='gray')
axes[0,1].set_title('L channel (Grayscale)')
axes[1,0].imshow(A, cmap='RdYlGn_r')
axes[1,0].set_title('A channel (Green-Red)')
axes[1,1].imshow(B, cmap='YlGnBu_r')
axes[1,1].set_title('B channel (Blue-Yellow)')
plt.tight_layout()
plt.show()Q note on video colourisation, while talking about it in upcoming blog posts. This apply to video, as videos are simply multiple frames run in a certain speed. Video colorization has issues because of flickering and inconsistent colourisation.
TLDR: How make sure colourisation from 1st frame still applies at frame 50th? see here - if you very eager beaver
Now you understand how image colourisation works we start describe the various architectures.
The Evolution of Colorization: CNN, User-Guided, and Exemplar-Based Approaches
Based on this paper, we classify 3 image colourization types. These are CNN-based, User-guided, and Exemplar-based. There are actually more types of image colourization, which you can see in this paper. But for historical imagery, these are the most relevant.
CNN based image colourisation is type we just explained above. All successive models are build on top on a CNN.
The computer does need see the greyscale and color images right?
The influential papers start started were Deep Colorization. Which showed how deep learning can be used for image colourisation. Using CNNs and early GANs and autoencoders. The next generation were real time user guided image colourisation, that introduced user input for image colourisation. And then, exemplar based image colourisation. Which introduced reference images for helping adjust models. Deep Colorization Paper
Check out the videos of Deep Colorisation below:
Real-Time User-Guided Image Colorization with Learned Deep PriorsColorful Image ColorizationReal-Time User-Guided Image Colorization with Learned Deep Priors (Aug 2017, SIGGRAPH)
These models are great, as they nudge the model in the right direction. As talked about with t-shirt examples image Colorization has a subjective element to it. It can be art as well as a science. (Which all of deep learning btw).
User-guided has the most entertaining examples. Like stickman to images and coloring anime. (If you're a weeboo). These User-guided tend to use GANs and large pre-trained models like a U-Net.
GANs are used because they help generate images, compared to CNNs. Which only classify images. Pretrained-network can already identify various features, shapes, lines etc. instead developing a model from scratch. So we can just focus on colourizing the image.
GANs are out of fashion now, thanks to diffusion models. (No, I wont be explain them here sorry. You are already maths up enough). If you're still interested check out this.
Plain Image Colourisation
This section will be on the shorter side, as the intro and the loss functions sections will explain most of the dynamics.
Let's deep dive into the deep colourisation paper, mentioned above with the video. Architecture is a simple 5 full connected linear layers with ReLU activations, and greyscale image taken as input for the CNN. Where the Output layer has two neurons for U and V color channel values.
Extracting the features are done in 3 levels Low-level the actual patches of gray values. mid level DAISY features a fancy name for general features and shapes and semantic labeling. Hard labels saying this is a tree or a car. Then using a post-processing technique called Joint Bilateral Filtering. Via measuring the spatial distance and the intensity difference between pixels.

Colorful Image Colorization, a great paper. The architecture was Eight blocks of stacked convolutional layers, with Each block contains 2-3 convolutional layers followed by ReLU and Batch Normalization. And Striding used instead of pooling for downsampling.
The cool thing here is how to manipulated the color space of the image. By predicting 313 "ab" pairs representing an empirical probability distribution. Via inference share the correct AB pair for the output image. Cool stuff right. This paper starts deal with the washout issue mentioned in the next section.
So the main trends here were how color representation changes, from direct U and V prediction to probability distributions over color space. Many objects can have multiple plausible colors. Predicted U and V values were forced to choose a single color, often resulting in "safe" but unrealistic predictions (like the infamous brown tendency). And upgrading CNNs via residual blocks and batch normalization and various activation functions. Are now a staple in modern deep learning.

User Guided Models
User guided and exemplar based models, provide feedback from user which a pixel or image reference is used. Popular within the literature right now.
Because the model provides more accurate results, via getting help from user and just relying on the training images seen before hand. A user this car should be red, this t-shirt should be white help model adjust from there.
Here's are great survey paper for more details: [2008.10774] Image Colorization: A Survey and Dataset (arxiv.org)
But what happens if the image is not historical accurate? (Hint, Hint: my paper). [move maybe]
Let's start with Scribbler, A model that allows users to add stokes into images were the model colourise the image based on these images. Via using feed forward network and GAN, to identify the sketch. This model applies a bounding box to the sketch and also previous trained on various shapes and sizes so it can provide accurate output.

[1612.00835] Scribbler: Controlling Deep Image Synthesis with Sketch and Color (arxiv.org)
Real-Time User-Guided Colorization: This papers allows the user to add "hints", pixels that on greyscale image that model should use. So you use a green pixel on a t-shirt. And guess what. The t-shirt is now colourised as green not red. This does not use GAN, but closer to the CNN architecture mentioned earlier. The global hint network keeps account of all the pixels in the image, not just the user input.


Hint-Guided Anime Colorization: A model that were you can draw anime sketches and the model colourizes it. Told you would you like this. This also you uses a C-GAN with U-NET. Used for the perceptual loss.


What makes user guided networks great, so it's downfall. These models can be laborious. Because you are effectively labeling each greyscale image before passing it into the model. Also, if a user selects an unnatural color, then this tends to lead the model to fail. (You won't see a purple dog in the wild, would you? 🤨)
Exemplar Based Models
Now we move on to exemplar models, the state of the art for image colourization. Best to think of this as the advanced version of user guided models. Here's we have reference images to guide the model what's great about this, reference image allows us whole range of pixels to use for colourised image. Not just a simple pixel or sketch like previous models showcased above.
For the exemplar based architecture, The reference image is a big deal, (DUH!). This means the architecture takes 2 inputs, reference image and the greyscale image. Best to think reference image a nudge or weight for the greyscale image. (something I built upon on my paper[link to my paper]).
There many techniques to implement this architecture, by using a single image for the reference and target, to using local references that adjust specific section of the target image.
Deep Exemplar-based Colorization

The paper that introduced exemplar-based colorization. The model has 2 main parts, A Similarity sub-network that measures semantic similarity between the reference and target using VGG features. And a colorization sub-network that learns to select, propagate and predict colors end-to-end. With two main branches, Chrominance branch - Learns to selectively propagate colors from well-matched regions. And the perceptual branch: Predicts plausible colors for unmatched regions based on large-scale data.

SPColor: Semantic Prior Guided Exemplar-based Image Colorization
Building upon the Deep Exemplar-based Colorization paper, SPColor introduces semantic information to guide the model. The main components include a semantic prior guided correspondence network (SPC), which identifies objects in the image; a category reduction algorithm (CRA), which develops about 22 semantic categories for efficient image processing; and a similarity masked perceptual loss (SMP loss), a custom loss function that combines perceptual loss with a similarity map to balance color preservation and generation.
The breakthrough in this paper is the use of semantic segmentation, allowing the model to understand spatial context in the image. For example, it can distinguish between a tree and a car, and colorize the image in local areas rather than all at once, helping to avoid mismatches between semantically different regions.


Here we can see how great exemplar based models are, and why there are the state of the art. From better accuracy to more control from the user. This approach demonstrates significant improvements over previous methods, particularly in handling complex scenes and preserving semantic consistency in the colorized images.
Loss Functions

taken from colorful image colourisation: 1603.08511 (arxiv.org)
But you can see the issues of the colourisation; most of the images are washed out, brown, or frankly incorrect. As the image struggles to identify different objects across images.
(Fun fact: The reason why all images start out as brown is because this is most common color it will see across the dataset. By picking this color it has the lowest error.)
Why Brown? - You might ask?
Many colorization models use MSE as their loss function. MSE penalizes large errors more heavily than small ones. Brown emerges as a compromise color that minimizes error across diverse scenes via averaging the color values.
Let's consider a simplified scenario:
- True colors: [255, 0, 0] (red), [0, 255, 0] (green), [0, 0, 255] (blue)
- Average color: [85, 85, 85] (a shade of gray/brown)
MSE for average color:
MSE = [(255-85)^2 + (0-85)^2 + (0-85)^2 +
(0-85)^2 + (255-85)^2 + (0-85)^2 +
(0-85)^2 + (0-85)^2 + (255-85)^2] / 9
≈ 14,167MSE for any specific color (e.g., red):
MSE = [(255-255)^2 + (0-255)^2 + (0-255)^2 +
(255-0)^2 + (255-255)^2 + (255-0)^2 +
(255-0)^2 + (255-0)^2 + (255-255)^2] / 9
≈ 43,350The average color yields a lower MSE, incentivize the model to predict "safe" brownish (and ugly) colors.
This is why Pixel-wise loss alone, don't cut it. They don't work for spatial relationships between colors in an image. AKA understanding what going in photos and the objects. (spatial context). Using a more technical term this leads to "mode collapse" [How to Identify and Diagnose GAN Failure Modes - MachineLearningMastery.com, Monitor GAN Training Progress and Identify Common Failure Modes - MATLAB & Simulink - MathWorks United Kingdom]. The model tends to converge on a limited set of "safe" colors, leading to the washed-out appearance.
Now you can see why designing good loss functions are important.
Loss function definitions
Due to adversarial nature of GANs it follows a MinMaxLoss function. With the generator and discriminator competing against each other. As generator develops better images to foll the discriminator that try the tell the difference between a generated and a real image. This concept is later used for perceptual loss in non-GAN models.
$$\min_ \max_ \mathbb{x \sim p\text[\log D(x)] + \mathbb_{z \sim p_z(z)}[\log(1 - D(G(z)))]$$
\(\min_{\max} \mathbb{E}_{x \sim p(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))]\)
Pixel-wise loss, directly compares the color values of each pixel in the generated colorized image to the corresponding pixel in the ground truth (target) color image. A traditional loss function, like MSE, MAE and L1.
Perceptual loss aims to capture higher-level features and textures that are important to human visual perception, rather than just pixel-level differences
The key idea is to use a pre-trained neural network (often a CNN classifier like VGG) to measure the similarity between the generated colorized image and the target ground truth image in the feature space of the pre-trained network 4. The intuition is that this perceptual loss can better guide the model to generate colorized images that look visually similar to the target, even if the pixel values don't match exactly 4. [perplexity.ai search]
Perceptual loss and Pixel-level loss are combined into a total loss function for the model.
L_total = λ_p * L_perceptual + λ_pix * L_pixelIn latex form: $$L_ = \lambda_p \cdot L_ + \lambda_ \cdot L_$$
Quick deep learning reminder, the lambda expressions are regularization parameters.
Maths Deep Dive for loss functions
Perpetual Loss

An example feature loss equation take from this paper: (PDF) Analysis of Different Losses for Deep Learning Image Colorization (2022) (typeset.io).
Let's breakdown what the formula says.
Understanding the Components:$C_l, W_l, H_l$:
- These symbols represent the number of channels ($C_l$), width ($W_l$), and height ($H_l$) of the image at layer $l$. Channels refer to color channels (like red, green, blue) or the LAB color space.
- Width and height are the dimensions of the image, which help in understanding the size of the data being processed.
The Norm $|\Phi_l(u) - \Phi_l(v)|_2^2$:
- The term $\Phi_l(u)$ and $\Phi_l(v)$ refers to the features extracted from images $u$ and $v$ at layer $l$.
- The notation $|\cdot|_2$ represents the L2 norm, which is a way to measure the distance between two points in space. In this case, it measures how different the features of the two images are.
- Squaring this distance (the $^2$ part) emphasizes larger differences, making them more significant in the loss calculation.
Why Divide by $C_l W_l H_l$?
- The division by $C_l W_l H_l$ normalizes the loss value. This means it adjusts the loss based on the size of the images and the number of features.
- Normalization is important because it allows for fair comparisons between different images or models, regardless of their size or complexity.
MSE
Also, some for technical details of MSE.

The formula for MSE in the continuous case.
Let's break this down step by step.
- Variables Explained:
- $u$ and $v$: These represent two different images or sets of data we are comparing. For example, 'u' could be the colorized version of a greyscale image, and 'v' could be the actual color image we want to achieve.
- $\Omega$: This symbol represents the area or domain over which we are comparing the two images. Think of it as the entire space of the image we are looking at.
- $$\mathbb{C}$$ This notation indicates that we are dealing with color information. 'C' represents the number of color channels (like Red, Green, and Blue). So, if we have a color image, 'C' would typically be 3.
- Understanding the Norm:
- $|u-v|_{L^2(\Omega; \mathbb{R})}$: This part of the formula calculates the difference between the two images $u$ and $v$ across the entire area $\Omega$. The $L^2$ indicates that we are using the squared differences, which is important for MSE.
- $|u(x)-v(x)|_2^2$: Here, $x$ represents a specific point in the image. This expression calculates the squared difference in color values at that point. The $2$ in the subscript indicates that we are using the Euclidean norm, which is a way to measure distance in a multi-dimensional space (like color).
- The Integral:
- $\int_\Omega$: This symbol means we are adding up (integrating) all the squared differences across the entire image. It helps us get a single number that represents the overall difference between the two images.

- Breaking Down the Formula discrete version:
The formula given is:
$$\text(u, v) = \sum_^M \sum_^N \sum_^C (u_ - v_)^2$$
$$\text{u, v} = \sum_{i=1}^M \sum_{j=1}^N \sum_{k=1}^C (u_{ijk} - v_{ijk})^2$$
$$\text{d}(u, v) = \|u-v\|_{L^2(\Omega; \mathbb{R}^2)} = \sqrt{\int_{\Omega} |u(x) - v(x)|_2^2 \, dx}$$
Here's what each part means:
- $u$ and $v$: These represent the two images we are comparing. $u$ is the colorized image, and $v$ is the original image.
- $M$: This is the height of the images in pixels. It tells us how many rows of pixels there are.
- $N$: This is the width of the images in pixels. It tells us how many columns of pixels there are.
- $C$: This represents the number of color channels in the images. For example, a typical color image has three channels: Red, Green, and Blue (RGB).
Understanding the Summation: The formula uses three summations (the $\sum$ symbols) to add up values:
- The first summation (over $i$) goes through each row of pixels.
- The second summation (over $j$) goes through each column of pixels.
- The third summation (over $k$) goes through each color channel.
This means we are looking at every single pixel in every color channel of both images.
Calculating the Difference: Inside the summation, we see $(u - v)^2$:
- This part calculates the difference between the color value of the pixel in the colorized image $u$ and the original image $v$ for each pixel at position $(i, j)$ and color channel $k$.
- The difference is then squared. Squaring the difference is important because it makes sure that we do not have negative values, and it emphasizes larger differences more than smaller ones.
MAE

$$\text(u, v) = \int_\Omega |u(x)-v(x)|_ dx$$
Here, $u$ and $v$ represent two different images. $u$ is the image that the model predicts (the colorized image), and $v$ is the actual image we want (the ground truth image).
The symbol $\int_\Omega$ means we are looking at all the pixels in the image. $\Omega$ represents the entire area of the image we are analyzing.
The integral helps us sum up the differences across all pixels in the image.
The term $|u(x)-v(x)|$ is a way to calculate the difference between the predicted color and the actual color for each pixel.
The $l^1$ norm specifically means we are taking the absolute value of the difference. This means we are only interested in how far apart the colors are, without worrying about whether one is greater or smaller than the other.
Summing Over Color Channels:
Here, $C$ represents the number of color channels in the image. For example, in a typical RGB image, there are three channels: Red, Green, and Blue.
The expression $|u_k(x) - v_k(x)|$ calculates the absolute difference for each color channel $k$ at a specific pixel $x$.
The entire formula calculates the total error across all pixels and all color channels. It tells us how well the model has done in predicting the colors.
The formula for MAE in the discrete case is:
$$\text{u, v}^c = \sum_{i=1}^M \sum_{j=1}^N \sqrt{c} (u_{ij} - v_{ij})$$
- Here, $u$ and $v$ represent two images. $u$ is the colored image produced by the computer, and $v$ is the original colored image we want to compare it to.
- $M$ and $N$ are the dimensions of the images. Specifically, $M$ is the number of rows (height) in the image, and $N$ is the number of columns (width).
- $c$ represents the number of color channels in the image. For example, a typical colored image has three channels: red, green, and blue (RGB).
- The formula uses a double summation, which means it adds up values in a systematic way. The first summation ($\sum_{i=1}^M$) goes through each row of the image, and the second summation ($\sum_{j=1}^N$) goes through each column.
- For each pixel located at position $(i, j)$, the formula calculates the difference between the predicted color value $u$ and the actual color value $v$ for each color channel $k$.
Discrete Settings vs Continuous Settings
Throughout this section, i've shown both discrete and continuous version of the same loss functions. So why do we have different versions of the same thing? (hopefully you remember some calculus)
Discrete Settings are used because images are represented as discrete pixel values. Loss functions like L1 and L2 operate on these pixel values, making them suitable for direct computation of differences between predicted and actual values .
Continuous Settings may involve treating pixel values as continuous variables, which can be beneficial for certain types of models that predict color distributions rather than specific values.
Code version of the Loss functions
# [from perplexity] (https://www.perplexity.ai/)
import torch
import torch.nn as nn
import torchvision.models as models
class SimplePerceptualLoss(nn.Module):
def __init__(self):
super(SimplePerceptualLoss, self).__init__()
# Load pre-trained VGG16 and use its first few layers
vgg = models.vgg16(pretrained=True)
self.feature_extractor = nn.Sequential(*list(vgg.features)[:5]).eval()
# Freeze the parameters
for param in self.feature_extractor.parameters():
param.requires_grad = False
def forward(self, generated, target):
# Extract features from generated and target images
gen_features = self.feature_extractor(generated)
target_features = self.feature_extractor(target)
# Compute mean squared error between features
loss = nn.MSELoss()(gen_features, target_features)
return loss
# Usage example
perceptual_loss = SimplePerceptualLoss()
# Example tensors representing generated and target images
generated = torch.randn(1, 3, 256, 256)
target = torch.randn(1, 3, 256, 256)
loss = perceptual_loss(generated, target)
print(f"Perceptual Loss: ")loss = nn.MSELoss()(gen_features, target_features) this is the main line. Comparing VGG features to the image colourisation features.
Funny you can create a loss function for everything, the lesson in deep learning. Go ask Sam Altman.
Main thing to keep in mind for image colorization, is that calculating the difference between the color and black and white images. Which used to adjust the model for colourisation.
Conclusion
As we've journeyed through the interesting world of image colorization, we've seen how this field has rapidly evolved from simple pixel-based techniques to advanced deep learning tools.
- We started with the basics of color theory and how computers interpret color spaces like RGB and LAB.
- We explored the fundamental role of Convolutional Neural Networks (CNNs) in modern colorization techniques.
- We traced the evolution of colorization methods, from plain CNN-based approaches to more advanced user-guided and exemplar-based models.
- We delved into the intricacies of loss functions, understanding how pixel-wise, perceptual, and GAN losses contribute to more accurate and visually pleasing results.
- Finally, we examined state-of-the-art exemplar-based models that leverage semantic information and reference images to produce more accurate colorization.
Within a decade the field of image colourisation via deep learning has progressed a lot. Makes you wonder what the next decade has in store with us. With LLMs and better image generation models. Let's see. Also i've opted moved the ethics and humanities section into a separate blog post. Questions like: what happens if image colourisation is not historical accurate what's next? Something that my paper does a deep dive in. Read my paper here
Coloring the Past: Using AI to Colorize Historical Images - Final Year Project
Envision what life would have been like in Victorian England, D-Day landings or even your grandparents' wedding day. My project, "Coloring the Past," aims to bring these black-and-white memories to life using AI techniques. You may ask if image colourisation already exists. So what's the big deal? Here my project focuses on historical accuracy not just pretty colours.
Here are some examples:




Project Overview and Objectives
My project uses Generative Adversarial Networks (GANs), to colorize historical black-and-white photographs. Unlike other methods, our approach ensures the colors are true to the historical period by using era-specific color palettes. This method not only enhances the visual appeal but also preserves historical authenticity.
Develop a more historically accurate image colouration model via colour palettes and new loss function that compares historical images vs normal image colourisation.
Compare our model with existing ones using quantitative and qualitative metrics.
Collect and annotate images from various periods and regions to train and test our model.

Why is Image Colorization Hard?
Turning Greyscale to color is no easy feat. Simply because we mapping a color space of 1 dimension (Only Greyscale) into 3 dimensions. (Red, Green, Blue). Without the amount of various shades and mixing we have 10M potential colours!
Technical Explanation and Methodology
My method builds on the SPColor architecture, an exemplar-based colorization approach using semantic matching.
Here's a simplified breakdown of our process:
1. Input: Start with a grayscale image.
2. Feature Extraction: Use a pre-trained CNN (like VGG-19) to understand the image's features.
3. Semantic Segmentation: Classify each pixel to identify objects (e.g., sky, tree).
4. Time Period Reference: Use a table linking historical periods to their typical colors of that era.
5. Color Scheme Generation: Combine labels, historical colors, and other data to create a color scheme.
6. Color Propagation: Apply these colours to the image.
7. Time Period Adjustment: Fine-tune colours to match the historical period accurately.

Impact and Applications
There is potential for this Machine learning model to be used in other fields. By making historical photos more realistic and engaging. Helping historians recover photos quicker. Allowing people media colorise images and video various documentary work.
If you're interested in my work feel to get in touch.
Machine Learning Image Restoration - How does Deoldify Work?
Written in March 2022
The main goal of this project is to understand the deoldify repo. This was a ML program created by the fastai community for recolaristion and super-resolution. This was the first project that came to my mind. There are numerous recolaristion project. That will be checking out as well.
The first week was trying to even run this. The model takes so much memory that it broke my PC. Leading to me removing and reinstalling anaconda. And my downloads folder. Which sucked. Deoldify has google colab version but it does not have a way to see the code used. As it’s simply an import.
I worked out that I could copy and paste the code from the python script into the notebook. By going through the python files and pasting them into cells. You could start to get an idea how the program worked on a high level. It could a while to get the cells in the right order so it could start working. As a cell will give errors for classes and methods not yet defined.
After changing the cells order and dealing with the imports. I started to get the program to work. I had to get the requirements text file. Which can be annoying in Google Colab due to the restarting nature of clearing out memory. But still got it to work.
First stage was adding comments to the code, helping me to slowly understand what the various methods did. Then I typed up most of the codebase that seem relevant to my use case. Doing this means I had to see the code first hand. Funny enough writing the code was not the hardest part. It was debugging the various errors from misspelling various class names. This was great because if something broke, I could see the logical flow of the program and see how the program interacts with other classes.
One of my most important steps I did was creating a diagram following the main functions and classes until they hit the standard library or the Fastai library. So I could see all code written that is not part a library. Great way to understand how the prograe worked on a high level.
I like to call it recursively learning. As I took the last function called, in the codebase then followed up all the way to the top of the notebook. It allows you to see various classes and methods that were called inside other classes. The code was written in a object-oriented manner. Hence the various classes and parameters being passed to various methods and subclasses.
This is a great codebase to look at. Well written code. Something to aspire to be honest. After understanding the main aspects it all snaps into piece. Great how the various classes relate to each other. While still using other libraries like fastai.
Summary of the Code
The codebase is set up in way that configurations like GPU settings are done first. Then a lot of time is spend building the architecture of U-net used for inference or training.
Due to the OOP nature of the code. The U-net is separated into various parts. We have custom layers and custom pixel shuffling which are separate classes. Which are then used in the Bigger U-Net class. And the U-Net consists of blocks which the custom layers are used. And inserted inside the U-net arch. To be more precise added between layers where the activation changes. After the U-Net arch is created the author uses other classes to create the Fastai learner object. This object is to train ML models in fastai. As we are using a pre-trained U-net. The object is used to load weights into the u-net arch. These various classes help pass though the image data into the ML model.
The most important class in the code base is the modelimageviewer. A class that takes in the image and calls on the ML model and extracts filters from it. Then passed out a filtered image that can be used for plotting. The methods that plot and save the images are stored in that class. Best to think of the modelimageviewer as a funnel.
Custom Layers
#layers.py
def custom_conv_layer(
ni: int, #number of inputs
nf: int, # number of filters / out_channel
ks: int = 3, # kernal size
stride: int = 1, # movment across image
padding: int = None,
bias: bool = None,
is_1d: bool = False,
norm_type: Optional[NormType] = NormType.Batch,
use_activ: bool = True,
leaky: float = None,
transpose: bool = False,
init: Callable = nn.init.kaiming_normal_,
self_attention: bool = False,
extra_bn: bool = False,
):
"Create a sequence of convolutional (`ni` to `nf`), ReLU (if `use_activ`) and batchnorm (if `bn`) layers."The parameters here are just settings you would see in any other convolutional layer. Extra settings include self attention.
if padding is None:
padding = (ks - 1) // 2 if not transpose else 0
bn = norm_type in (NormType.Batch, NormType.BatchZero) or extra_bn == True
if bias is None:
bias = not bn
conv_func = nn.ConvTranspose2d if transpose else nn.Conv1d if is_1d else nn.Conv2d
conv = init_default(
conv_func(ni, nf, kernel_size=ks, bias=bias, stride=stride, padding=padding),
init,
)
if norm_type == NormType.Weight:
conv = weight_norm(conv)
elif norm_type == NormType.Spectral:
conv = spectral_norm(conv)
layers = [conv]
if use_activ:
layers.append(relu(True, leaky=leaky))
if bn:
layers.append((nn.BatchNorm1d if is_1d else nn.BatchNorm2d) (nf))
if self_attention:
layers.append(SelfAttention(nf))
return nn.Sequential(*layers)This is the first cell we start work on creating the architecture and model. Here a custom convolution layer is built. On the GitHub page it says: “Except the generator is a pretrained U-Net, and I've just modified it to have the spectral normalization and self-attention. It's a pretty straightforward translation.” We added options of spectral and self attention in this cell.
elif norm_type == NormType.Spectral:
conv = spectral_norm(conv)
if self_attention:
layers.append(SelfAttention(nf))Fastai classes added to the layer.
class CustomPixelShuffle_ICNR(nn.Module):
"Upsample by `scale` from `ni` filters to `nf` (default `ni`),"
def __init__(
self,
ni: int,
nf: int = None,
scale: int = 2,
blur: bool = False,
leaky: float = None,
**kwargs
):
super().__init__()
nf = ifnone(nf, ni) #ifnone: Fast.ai core.py
self.conv = custom_conv_layer(
ni, nf * (scale ** 2), ks=1, use_activ=False, **kwargs
)
icnr(self.conv[0].weight)
self.shuf = nn.PixelShuffle(scale)
# Blurring over (h*w) kernel
# "Super-Resolution using Convolutional Neural Networks without Any Checkerboard Artifacts"
# - https://arxiv.org/abs/1806.02658
self.pad = nn.ReplicationPad2d((1, 0, 1, 0))
self.blur = nn.AvgPool2d(2, stride=1)
self.relu = relu(True, leaky=leaky)
def forward(self, x):
x = self.shuf(self.relu(self.conv(x)))
return self.blur(self.pad(x)) if self.blur else xPixel shuffling works as follows, we take an low-resolution image then we create an sub-pixel image by adding around and between the original pixels. Then we use an kernel to pass though the sub-pixel image activating the weights activating with the pixels. Some pixels are by non-zero pixel, some with padding etc.
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network: https://arxiv.org/abs/1609.05158
Add-on to the previous papers: https://arxiv.org/abs/1609.07009
U-Net Arch
class UnetBlockDeep(nn.Module):
"A quasi-UNet block, using `PixelShuffle_ICNR upsampling`. using `nn.PixelShuffle`, `icnr` init, and `weight_norm`."
def __init__(
self,
up_in_c: int,
x_in_c: int,
hook: Hook,
final_div: bool = True,
blur: bool = False,
leaky: float = None,
self_attention: bool = False,
nf_factor: float = 1.0,
**kwargs
):
super().__init__()
self.hook = hook
self.shuf = CustomPixelShuffle_ICNR(
up_in_c, up_in_c // 2, blur=blur, leaky=leaky, **kwargs
)
self.bn = batchnorm_2d(x_in_c)
ni = up_in_c // 2 + x_in_c
nf = int((ni if final_div else ni // 2) * nf_factor)
self.conv1 = custom_conv_layer(ni, nf, leaky=leaky, **kwargs)
self.conv2 = custom_conv_layer(
nf, nf, leaky=leaky, self_attention=self_attention, **kwargs
)
self.relu = relu(leaky=leaky)
def forward(self, up_in: Tensor) -> Tensor:
s = self.hook.stored
up_out = self.shuf(up_in)
ssh = s.shape[-2:]
if ssh != up_out.shape[-2:]:
up_out = F.interpolate(up_out, s.shape[-2:], mode='nearest')
cat_x = self.relu(torch.cat([up_out, self.bn(s)], dim=1))
return self.conv2(self.conv1(cat_x))Now we create a class with conv and pixel shuffling from earlier. Inside the class we define how they layers will be used. We store the pixel_shuffle in self.shuf. We define batchNorm and the 2 convolutional layers. One with self attention and one with a RELU layer.
When creating the forward method we create a variable to help save the stored hooks. This is done Because we will use the hooks to get the number of activations for each layer. The up-sample is created from an pixel shuffle.
Afterwards the data is contracted and passed though a relu function. Which is passed through two convolutional layers.
class DynamicUnetDeep(SequentialEx):
"Create a U-net from a given architecture"
def __init__(
self,
encoder: nn.Module,
n_classes: int,
blur: bool = False,
blur_final=True,
self_attention: bool = False,
y_range: Optional[Tuple[float, float]] = None,
last_cross: bool = True,
bottle: bool = False,
norm_type: Optional[NormType] = NormType.Batch,
nf_factor: float = 1.0,
**kwargs
):
extra_bn = norm_type == NormType.Spectral
imsize = (256, 256) #image size
# sfs = save features???
sfs_szs = model_sizes(encoder, size=imsize) #model sizes sfs???
print('sfs_szs_DynamicUnetDeep: ', sfs_szs)
sfs_idxs = list(reversed(_get_sfs_idxs(sfs_szs))) # sfs IDs
print('sfs_idxs_sfs_szs_DynamicUnetDeep:', sfs_idxs)
self.sfs = hook_outputs([encoder[i] for i in sfs_idxs]) # store weights
print('self.sfs: ', self.sfs)
x = dummy_eval(encoder, imsize).detach() # dummy input to set up model
ni = sfs_szs[-1][1]
middle_conv = nn.Sequential(
custom_conv_layer(
ni, ni * 2, norm_type=norm_type, extra_bn=extra_bn, **kwargs
),
custom_conv_layer(
ni * 2, ni, norm_type=norm_type, extra_bn=extra_bn, **kwargs
),
).eval()
x = middle_conv(x)
layers = [encoder, batchnorm_2d(ni), nn.ReLU(), middle_conv]
for i, idx in enumerate(sfs_idxs):
not_final = i != len(sfs_idxs) - 1
up_in_c, x_in_c = int(x.shape[1]), int(sfs_szs[idx][1])
do_blur = blur and (not_final or blur_final)
sa = self_attention and (i == len(sfs_idxs) - 3)
unet_block = UnetBlockDeep(
up_in_c,
x_in_c,
self.sfs[i],
final_div=not_final,
blur=blur,
self_attention=sa,
norm_type=norm_type,
extra_bn=extra_bn,
nf_factor=nf_factor,
**kwargs
).eval()
layers.append(unet_block)
x = unet_block(x)
ni = x.shape[1]
if imsize != sfs_szs[0][-2:]:
layers.append(PixelShuffle_ICNR(ni, **kwargs))
if last_cross:
layers.append(MergeLayer(dense=True))
ni += in_channels(encoder)
layers.append(res_block(ni, bottle=bottle, norm_type=norm_type, **kwargs))
layers += [
custom_conv_layer(ni, n_classes, ks=1, use_activ=False, norm_type=norm_type)
]
if y_range is not None:
layers.append(SigmoidRange(*y_range))
super().__init__(*layers)Breakdown of the class
def __init__(
self,
encoder: nn.Module,
n_classes: int,
blur: bool = False,
blur_final=True,
self_attention: bool = False,
y_range: Optional[Tuple[float, float]] = None,
last_cross: bool = True,
bottle: bool = False,
norm_type: Optional[NormType] = NormType.Batch,
nf_factor: float = 1.0,
**kwargs
):We will pass the U-net via the encoder argument. We have some settings like blur, used for the sigmoidal activation function.
This paper talks about it https://arxiv.org/abs/1806.02658
After we create all the layers and blocks. We can stack them together to built the U-net architecture.
When the class is called later on we would be using resnet for the weights.
extra_bn = norm_type == NormType.Spectral
imsize = (256, 256) #image size
sfs_szs = model_sizes(encoder, size=imsize)We use Spectral for batch_norm. Define image size. And sfs_szs size of features for the resnet model.
sfs_idxs = list(reversed(_get_sfs_idxs(sfs_szs))) # sfs IDs
self.sfs = hook_outputs([encoder[i] for i in sfs_idxs]) # store weightssfs_idxs lets us grab the layers which the activation has changed. This where we would insert our U-net blocks into the resnet. Self.sfs is simply a way of storing the features of the various layers we want to change.
ni = sfs_szs[-1][1]
middle_conv = nn.Sequential(
custom_conv_layer(
ni, ni * 2, norm_type=norm_type, extra_bn=extra_bn, **kwargs
),
custom_conv_layer(
ni * 2, ni, norm_type=norm_type, extra_bn=extra_bn, **kwargs
),
).eval()We define the number of inputs that will be funnelled into the convolutional layers.
The convolutional layers are stacked together using the Pytorch sequential function.
layers = [encoder, batchnorm_2d(ni), nn.ReLU(), middle_conv]We have list of layers that now stacked together to create the U-net. We have the resnet layers first, then a batch_norm, RELU layer. And some convolutional layers.
for i, idx in enumerate(sfs_idxs):
not_final = i != len(sfs_idxs) - 1
up_in_c, x_in_c = int(x.shape[1]), int(sfs_szs[idx][1])
do_blur = blur and (not_final or blur_final)
sa = self_attention and (i == len(sfs_idxs) - 3)
unet_block = UnetBlockDeep(
up_in_c,
x_in_c,
self.sfs[i],
final_div=not_final,
blur=blur,
self_attention=sa,
norm_type=norm_type,
extra_bn=extra_bn,
nf_factor=nf_factor,
**kwargs
).eval()
layers.append(unet_block)
x = unet_block(x)for i, idx in enumerate(sfs_idxs) creates a counter while looping though the selected resnet layers. Helps us keep track of the layers we interating in the list.
not_final = i != len(sfs_idxs) - 1Saves the position of the final layer
up_in_c, x_in_c = int(x.shape[1]), int(sfs_szs[idx][1])do_blur = blur and (not_final or blur_final)
sa = self_attention and (i == len(sfs_idxs) - 3)We get the position of the where to do the blur effect when blur is true. And it’s not the layer nor the final blur layer. Position to place self-attention, is 3 places before final layer.
unet_block = UnetBlockDeep(
up_in_c,
x_in_c,
self.sfs[i],
final_div=not_final,
blur=blur,
self_attention=sa,
norm_type=norm_type,
extra_bn=extra_bn,
nf_factor=nf_factor,
**kwargs
).eval()
layers.append(unet_block)
x = unet_block(x)These variables are now passed as arguments for the unet block.
ni = x.shape[1]
if imsize != sfs_szs[0][-2:]:
layers.append(PixelShuffle_ICNR(ni, **kwargs))
if last_cross:
layers.append(MergeLayer(dense=True))
ni += in_channels(encoder)
layers.append(res_block(ni, bottle=bottle, norm_type=norm_type, **kwargs))When imsize does not match the current layer we can use the pixelshuffle almost like a upsample. Remember a lot of this code is based on this repo [insert link to docs and colab] https://docs.fast.ai/vision.models.unet.html
def get_colorize_data(
sz: int,
bs: int,
crappy_path: Path,
good_path: Path,
random_seed: int = None,
keep_pct: float = 1.0,
num_workers: int = 8,
stats: tuple = imagenet_stats,
xtra_tfms=[],
) -> ImageDataBunch:
src = (
ImageImageList.from_folder(crappy_path, convert_mode='RGB')
.use_partial_data(sample_pct=keep_pct, seed=random_seed)
.split_by_rand_pct(0.1, seed=random_seed)
)
data = (
src.label_from_func(lambda x: good_path / x.relative_to(crappy_path))
.transform(
get_transforms(
max_zoom=1.2, max_lighting=0.5, max_warp=0.25, xtra_tfms=xtra_tfms
),
size=sz,
tfm_y=True
)
.databunch(bs=bs, num_workers=num_workers, no_check=True)
.normalize(stats, do_y=True)
)
data.c = 3
return dataThis is pretty much a helper function. Create a dummy databuch object. To help export the weights of pretrained dataset.
def get_dummy_databunch() -> ImageDataBunch:
path = Path('./dummy/')
return get_colorize_data(
sz=1, bs=1, crappy_path=path, good_path=path, keep_pct=0.001
)Here we just use the get_colorise_data function we declared earlier.
Now we start with the Ifilter abstract class:
class IFilter(ABC):
@abstractmethod
def filter(
self, orig_image: PilImage, filtered_image: PilImage, render_factor: int
) -> PilImage:
passWe import the ABC to make it into an abstract class. We create an abstract method which will be used for the other classes that inherit Ifilter. The abstract method simply takes in the original image, filtered image and render factor. And returns are PILimage
Render factor sets the resolution of the image. The higher the resolution factor the pixels the model gets to play with. But results vary per image. So you want try out a whole range to get the intended results for your image.
class BaseFilter(IFilter):
def __init__(self, learn: Learner, stats: tuple = imagenet_stats):
super().__init__()
self.learn = learn
if not device_settings.is_gpu():
self.learn.model = self.learn.model.cpu()
self.device = next(self.learn.model.parameters()).device
self.norm, self.denorm = normalize_funcs(*stats)
def _transform(self, image: PilImage) -> PilImage:
return image
def _scale_to_square(self, orig: PilImage, targ: int) -> PilImage:
# simple stretch to fit a square really make a big difference in rendering quality/consistency.
# I've tried padding to the square as well (reflect, symetric, constant, etc). Not as good!
targ_sz = (targ, targ)
return orig.resize(targ_sz, resample=PIL.Image.BILINEAR)
def _get_model_ready_image(self, orig: PilImage, sz: int) -> PilImage:
result = self._scale_to_square(orig, sz)
result = self._transform(result)
return result
def _model_process(self, orig: PilImage, sz: int) -> PilImage:
model_image = self._get_model_ready_image(orig, sz)
x = pil2tensor(model_image, np.float32)
x = x.to(self.device)
x.div_(255)
x, y = self.norm((x,x), do_x=True)
try:
result = self.learn.pred_batch(
ds_type=DatasetType.Valid, batch=(x[None], y[None]), reconstruct=True
)
except RuntimeError as rerr:
if 'memory' not in str(rerr):
raise rerr
print('Warning: render_factor was set too high, and out of memory error resulted. Returning original image.')
return model_image
out = result[0]
out = self.denorm(out.px, do_x=False)
out = image2np(out * 255).astype(np.uint8)
return PilImage.fromarray(out)
def _unsquare(self, image: PilImage, orig: PilImage) -> PilImage:
targ_sz = orig.size
image = image.resize(targ_sz, resample=PIL.Image.BILINEAR)
return imageBaseFilter will be used for the other filter classes that will be used next. The class creates helper methods to help take in an image and turn them into arrays and vice versa.
def __init__(self, learn: Learner, stats: tuple = imagenet_stats):
super().__init__()
self.learn = learn
if not device_settings.is_gpu():
self.learn.model = self.learn.model.cpu()
self.device = next(self.learn.model.parameters()).device
self.norm, self.denorm = normalize_funcs(*stats)For the initialisation function the Leaner object is passed. Then we set up device settings. As pass the model into the device. We also setup the batch norms with the stats arg.
def _transform(self, image: PilImage) -> PilImage:
return image
def _scale_to_square(self, orig: PilImage, targ: int) -> PilImage:
# simple stretch to fit a square really make a big difference in rendering quality/consistency.
# I've tried padding to the square as well (reflect, symetric, constant, etc). Not as good!
targ_sz = (targ, targ)
return orig.resize(targ_sz, resample=PIL.Image.BILINEAR)Internal functions helped to use maniplate PILimages. _transform return simple Pilimage. Done so it can used to passed into other methods.
Scale to square, stretching the image into square tends to improve performance.
def _get_model_ready_image(self, orig: PilImage, sz: int) -> PilImage:
result = self._scale_to_square(orig, sz)
result = self._transform(result)
return resultWe get an PIL_image which has been transformed and ready to be passed into the model.
def _model_process(self, orig: PilImage, sz: int) -> PilImage:
model_image = self._get_model_ready_image(orig, sz)
x = pil2tensor(model_image, np.float32)
x = x.to(self.device)
x.div_(255)
x, y = self.norm((x,x), do_x=True)
try:
result = self.learn.pred_batch(
ds_type=DatasetType.Valid, batch=(x[None], y[None]), reconstruct=True
)
except RuntimeError as rerr:
if 'memory' not in str(rerr):
raise rerr
print('Warning: render_factor was set too high, and out of memory error resulted. Returning original image.')
return model_image
out = result[0]
out = self.denorm(out.px, do_x=False)
out = image2np(out * 255).astype(np.uint8)
return PilImage.fromarray(out)def _unsquare(self, image: PilImage, orig: PilImage) -> PilImage:
targ_sz = orig.size
image = image.resize(targ_sz, resample=PIL.Image.BILINEAR)
return imageThis method undoes the fitting into square from earlier.
ColouriseFilter helps create the recolored image:
class ColorizerFilter(BaseFilter):
def __init__(self, learn: Learner, stats: tuple = imagenet_stats):
super().__init__(learn=learn, stats=stats)
self.render_base = 16
# only loads the instance when used the modelimagevisualiser
def filter(
self, orig_image: PilImage, filtered_image: PilImage, render_factor: int, post_process: bool = True
) -> PilImage:
render_sz = render_factor * self.render_base
model_image = self._model_process(orig=filtered_image, sz=render_sz)
raw_color = self._unsquare(model_image, orig_image)
if post_process:
print('self._post_process(raw_color, orig_image)', type(self._post_process(raw_color, orig_image)))
return self._post_process(raw_color, orig_image)
else:
print(raw_color)
return raw_color
def _transform(self, image: PilImage) -> PilImage:
print('image.convert(LA).convert(RGB)', type(image.convert('LA').convert('RGB')))
return image.convert('LA').convert('RGB')
def _post_process(self, raw_color: PilImage, orig: PilImage) -> PilImage:
color_np = np.asarray(raw_color)
orig_np = np.asarray(orig)
color_yuv = cv2.cvtColor(color_np, cv2.COLOR_BGR2YUV)
# do a black and white transform first to get better luminance values
orig_yuv = cv2.cvtColor(orig_np, cv2.COLOR_BGR2YUV)
hires = np.copy(orig_yuv)
hires[:, :, 1:3] = color_yuv[:, :, 1:3]
final = cv2.cvtColor(hires, cv2.COLOR_YUV2BGR)
final = PilImage.fromarray(final)
print('final', type(final))
return final
def filter(
self, orig_image: PilImage, filtered_image: PilImage, render_factor: int, post_process: bool = True
) -> PilImage:
render_sz = render_factor * self.render_base
model_image = self._model_process(orig=filtered_image, sz=render_sz)
raw_color = self._unsquare(model_image, orig_image)
if post_process:
print('self._post_process(raw_color, orig_image)', type(self._post_process(raw_color, orig_image)))
return self._post_process(raw_color, orig_image)
else:
print(raw_color)
return raw_colorThis filter method allows to extract giving filters need to colourise the image.
It inherits the BaseFilter so it can use the helper methods created earlier. We create another filter method same parameters from the Ifilter with post_process as well.
render_sz = render_factor * self.render_base
model_image = self._model_process(orig=filtered_image, sz=render_sz)
raw_color = self._unsquare(model_image, orig_image)We get the render size, by multiplying the render_factor with render_base. We create an image ready to be put into the model. With the model_process helper function. Then we extract the colours with _unsquare.
if post_process:
return self._post_process(raw_color, orig_image)
else:
return raw_colorWe return the post_process object or raw_color if post_process is True as a argument.
def _transform(self, image: PilImage) -> PilImage:
return image.convert('LA').convert('RGB')def _post_process(self, raw_color: PilImage, orig: PilImage) -> PilImage:
color_np = np.asarray(raw_color)
orig_np = np.asarray(orig)
color_yuv = cv2.cvtColor(color_np, cv2.COLOR_BGR2YUV)
# do a black and white transform first to get better luminance values
orig_yuv = cv2.cvtColor(orig_np, cv2.COLOR_BGR2YUV)
hires = np.copy(orig_yuv)
hires[:, :, 1:3] = color_yuv[:, :, 1:3]
final = cv2.cvtColor(hires, cv2.COLOR_YUV2BGR)
final = PilImage.fromarray(final)
print('final', type(final))
return finalWe create another _post_process method. We turn the image into numpy arrays to do operations on them.
color_np = np.asarray(raw_color)
orig_np = np.asarray(orig)
color_yuv = cv2.cvtColor(color_np, cv2.COLOR_BGR2YUV)
# do a black and white transform first to get better luminance values
orig_yuv = cv2.cvtColor(orig_np, cv2.COLOR_BGR2YUV)
hires = np.copy(orig_yuv)
hires[:, :, 1:3] = color_yuv[:, :, 1:3]
final = cv2.cvtColor(hires, cv2.COLOR_YUV2BGR)
final = PilImage.fromarray(final)MasterFilter is class that will store all gathered filters collected.
class MasterFilter(BaseFilter):
def __init__(self, filters: List[IFilter], render_factor: int):
self.filters = filters
self.render_factor = render_factor
def filter(
self, orig_image: PilImage, filtered_image: PilImage, render_factor: int = None, post_process: bool = True) -> PilImage:
render_factor = self.render_factor if render_factor is None else render_factor
for filter in self.filters:
filtered_image = filter.filter(orig_image, filtered_image, render_factor, post_process)
return filtered_imageThe class takes in a list of filters and the render factor. Another filter method is created Same parameters as before. Here the render factor is defined taking in the render_factor as an argument. If not it will use the default render factor.
Then it has a loop going though all the filters and applying the filter method to them.
ModelViewerVisualer
class ModelImageVisualizer:
def __init__(self, filter: IFilter, results_dir: str = None):
self.filter = filter
self.results_dir = None if results_dir is None else Path(results_dir)
self.results_dir.mkdir(parents=True, exist_ok=True)ModelImageVisualizer one of the most important classes in this whole repo. The reason why is gathers the rest of the object in the repo the FastAI learner, filters and coverts them into a viewable image. All of all work from above will not be used in this class allowing us to see the results.
The ModelImageVisualizer(MIV) creates numerous helper functions to manipulate the image. I will talk about the most important ones.
def _get_image_from_url(self, url: str) -> Image:
response = requests.get(url,timeout=30, headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'} )
img = PIL.Image.open(BytesIO(response.content)).convert('RGB')
return imgThis gets an PIL image from an url. This will be used for the next method.
def plot_transformed_image_from_url(
self,
url: str,
path: str = 'test_images/image.png',
results_dir: Path = None,
figsize: Tuple[int, int] = (20, 20),
render_factor: int = None,
display_render_factor: bool = False,
compare: bool = False,
post_process: bool = True,
watermarked: bool = True,
) -> Path:
img = self._get_image_from_url(url)
img.save(path)
# print('results_dir: ', results_dir)
return self.plot_transformed_image(path=path,
results_dir=results_dir,
figsize=figsize,
render_factor=render_factor,
display_render_factor=display_render_factor,
compare=compare,
post_process=post_process,
watermarked=watermarked)def plot_transformed_image_from_url(
self,
url: str,
path: str = 'test_images/image.png',
results_dir: Path = None,
figsize: Tuple[int, int] = (20, 20),
render_factor: int = None,
display_render_factor: bool = False,
compare: bool = False,
post_process: bool = True,
watermarked: bool = True,
) -> Path:
img = self._get_image_from_url(url)
img.save(path)
# print('results_dir: ', results_dir)
return self.plot_transformed_image(path=path,
results_dir=results_dir,
figsize=figsize,
render_factor=render_factor,
display_render_factor=display_render_factor,
compare=compare,
post_process=post_process,
watermarked=watermarked)We have a lot parameters for this method. Mainly because we passing arguments about storing the image and where to get it from. Also extra parameters for plotting options when the colorization is complete.
img = self._get_image_from_url(url)
img.save(path)We use the get image from url earlier. And have it inside a dummy folder.
Afterwards
return self.plot_transformed_image(path=path,
results_dir=results_dir,
figsize=figsize,
render_factor=render_factor,
display_render_factor=display_render_factor,
compare=compare,
post_process=post_process,
watermarked=watermarkedWe pass the image into the plot_transformed_image. This passes the arguments from this method into the plot_transformed_image. We can see arguments are passed to various methods
def plot_transformed_image(
self,
path: str,
results_dir: Path = None,
figsize: Tuple[int, int] = (20, 20),
render_factor: int = None,
display_render_factor: bool = False,
compare: bool = False,
post_process: bool = True,
watermarked: bool = True,
) -> Path:
path = Path(path)
if results_dir is None:
results_dir = Path(self.results_dir)
result = self.get_transformed_image(
path, render_factor, post_process=post_process, watermarked=watermarked
)
orig = self._open_pil_image(path)We load path into a variable. Then we check if the results is empty. If so, then we create a path for results directory. The result of the colorised image will be saved results varible. Which the get_trasformed_image from earlier will be called.
orig = self._open_pil_image(path)We get the original non-coloured image and save in org varible. This will be used for image comparison.
if compare:
self._plot_comparison(
figsize, render_factor, display_render_factor, orig, result
)
else:
self._plot_solo(figsize, render_factor, display_render_factor, result)If we have the compare argument set to true. Then we would call plot_comparsion if not we just plot the colorized result.
If you noticed by now, that sizeable chuck are helper functions. Allows you interact will the model the easiest way possible. With fiddling with small details.
orig.close()
result_path = self._save_result_image(path, result, results_dir=results_dir)
result.close()
return result_pathWe close the paths of images and we save result image in the results folder.
def _plot_comparison(
self,
figsize: Tuple[int, int],
render_factor: int,
display_render_factor: bool,
orig: Image,
result: Image,
):
fig, axes = plt.subplots(1, 2, figsize=figsize)
self._plot_image(
orig,
axes=axes[0],
figsize=figsize,
render_factor=render_factor,
display_render_factor=False,
)
self._plot_image(
result,
axes=axes[1],
figsize=figsize,
render_factor=render_factor,
display_render_factor=display_render_factor,
)Simple matplotlib plots, wont go into detail with this one.
def _plot_solo(
self,
figsize: Tuple[int, int],
render_factor: int,
display_render_factor: bool,
result: Image,
):
fig, axes = plt.subplots(1, 1, figsize=figsize)
self._plot_image(
result,
axes=axes,
figsize=figsize,
redner_factor=render_factor,
display_render_factor=display_render_factor,Save results of image
def _save_result_image(self, source_path: Path, image: Image, results_dir = None) -> Path:
if results_dir is None:
results_dir = Path(self.results_dir)
result_path = results_dir / source_path.name
image.save(result_path)
return result_pathThis internal method was called in transformed image. The method simply takes in the source_path of image. And the PIL image itself. The method saves image inside the results directory with name attached.
def get_transformed_image(
self, path: Path, render_factor: int = None, post_process: bool = True,
watermarked: bool = True
) -> Image:
self._clean_mem()
orig_image = self._open_pil_image(path)
filtered_image = self.filter.filter(
orig_image, orig_image, render_factor=render_factor,post_process=post_process
)
if watermarked:
return get_watermarked(filtered_image)
return filtered_imagedef _plot_image(
self,
image: Image,
render_factor: int,
axes: Axes = None,
figsize=(20,20),
display_render_factor = False,
):
if axes is None:
_, axes = plt.subplots(figsize=figsize)
axes.imshow(np.asarray(image) / 255)
axes.axis('off')
if render_factor is not None and display_render_factor:
plt.txt(
10,
10,
'render_factor: ' + str(render_factor),
color='white',
backgroundcolor='black',
)Internal method to help plot the images.
Now lets creating Fastai Learner. So we can export out Unet:
def unet_learner_deep(
data: DataBunch,
arch: Callable,
pretrained: bool = True,
blur_final: bool = True,
norm_type: Optional[NormType] = NormType,
split_on: Optional[SplitFuncOrIdxList] = None,
blur: bool = False,
self_attention: bool = False,
y_range: Optional[Tuple[float, float]] = None,
last_cross: bool = True,
bottle: bool = False,
nf_factor: float = 1.5,
**kwargs: Any
) -> Learner:Most of these parameters should be familiar to you. As we defined many of them when creating the U-net arch.
"Build Unet learner from `data` and `arch`."
meta = cnn_config(arch)
body = create_body(arch, pretrained)
model = to_device(
DynamicUnetDeep(
body,
n_classes=data.c,
blur=blur,
blur_final=blur_final,
self_attention=self_attention,
y_range=y_range,
norm_type=norm_type,
last_cross=last_cross,
bottle=bottle,
nf_factor=nf_factor
),
data.device,
)We get the metadata of the U-net. The we cut the U-net using the create_body method. Then we run the DyamicUnetDeep class into the device. We pass the body as the encoder.
learn = Learner(data, model, **kwargs)
learn.split(ifnone(split_on, meta['split']))
if pretrained:
learn.freeze()
apply_init(model[2], nn.init.kaiming_normal_)
return learnWe store the learner object in a variable
https://fastai1.fast.ai/basic_train.html#Learner.split
As the layers are pretrained we can use spilt function to create layer groups. As freeze the weights that we don’t want adjusted. The we use the appy_init function to initalise the layers.
def gen_learner_deep(data: ImageDataBunch, gen_loss, arch=models.resnet34, nf_factor: float = 1.5) -> Learner:
return unet_learner_deep(
data,
arch,
wd=1e-3,
blur=True,
norm_type=NormType.Spectral,
self_attention=True,
y_range=(-3.0, 3.0),
loss_func=gen_loss,
nf_factor=nf_factor,
)This class helps abstracts away the details of the unet_learner_deep class. Making it more user friendly.
# Weights are implicitly read from ./models/ folder
def gen_inference_deep(
root_folder: Path, weights_name: str, arch=models.resnet34, nf_factor: float = 1.5) -> Learner:
data = get_dummy_databunch() # use a placeholder data, to help export pretrained model
learn = gen_learner_deep(
data=data, gen_loss=F.l1_loss, arch=arch, nf_factor=nf_factor
)
learn.path = root_folder
learn.load(weights_name)
learn.model.eval()
return learnHere we pass dummy data, as we not training the model. We create class that will that take in pretrained weights and funnel them into the model.
def get_artistic_image_colorizer(
root_folder: Path = Path('./'),
weights_name: str = 'ColorizeArtistic_gen',
results_dir='result_images',
render_factor: int = 35,
) -> ModelImageVisualizer:
learn = gen_inference_deep(root_folder=root_folder, weights_name=weights_name)
filtr = MasterFilter([ColorizerFilter(learn=learn)], render_factor=render_factor)
print('filter', filtr)
vis = ModelImageVisualizer(filtr, results_dir=results_dir)
print('vis', vis)
return visNow all of the helper classes we created are now coming to together. We will pass the weights and the directory of the results. We first define the learner object. With root path and weight name being passed. Then we collected filtered images from MasterFilter from the ColorizerFilter. The learn object is passed as argument because we are using the U-net to extract filters from the Image.
Now it comes together with modelimagevisualiser
def get_image_colorizer(root_folder: Path = Path('./'), render_factor: int = 35, artistic: bool = True) -> ModelImageVisualizer:
if artistic:
return get_artistic_image_colorizer(root_folder=root_folder, render_factor=render_factor)
else:
return get_stable_image_colorizer(root_folder=root_folder, render_factor=render_factor)Another helper function that allows us to decide between different colorizers. Stable leads to less failure modes. But look washed out. Artistic colorizer has great results but more likely to break.
def show_image_in_notebook(image_path: Path):
ipythondisplay.display(ipythonimage(str(image_path))) #put into classNow starting the program
!mkdir 'models'
!wget https://data.deepai.org/deoldify/ColorizeArtistic_gen.pth -O ./models/ColorizeArtistic_gen.pthcolorizer = get_image_colorizer(artistic=True)We call the colorizer
!mkdir test_images
!touch placeholder.txtWe create a placeholder folder and file, bug in code.
source_url = 'https://i.imgur.com/AIpVTYQ.jpeg' #@param {type:"string"}
render_factor = 35 #@param {type: "slider", min: 7, max: 40}
watermarked = True #@param {type:"boolean"}
if source_url is not None and source_url !='':
image_path = colorizer.plot_transformed_image_from_url(url=source_url, render_factor=render_factor, compare=True, watermarked=watermarked)
show_image_in_notebook(image_path)
else:
print('Provide an image url and try again.')Now we pass in the source_url and the render factor.
if source_url is not None and source_url !='':
image_path = colorizer.plot_transformed_image_from_url(url=source_url, render_factor=render_factor, compare=True, watermarked=watermarked)Checks if source url is empty. Then calls the plot_transfomed image. Which are image (source_url) is passed to.
show_image_in_notebook(image_path)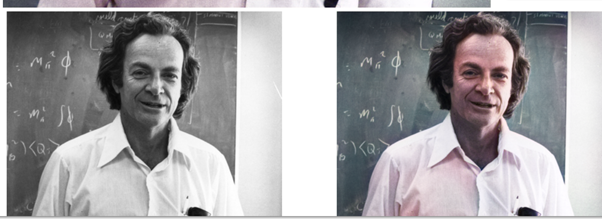
There is a lot of details that I missed, like how precisely does U-net convert a Black and white photo in color form. I don’t have a firm answer. How do some accepts like blur work. I decide to cut these because the project timeline was taking way to long.
If you like more of my projects, I provide occasional updates on my email list. Follow me on twitter and send me a DM. I want to meet new people in the ML space.
Likely will be working on diffusion models next or some type ESG/climate data project.
The $3 Trillion Showdown to Save the Planet
I was introduced to this report by Aaron McCreary from Doconomy. After asking for resources to learn about climate fintech. The report gave a rundown of the trends and categories of the industry.
When it comes to climate change finance is something we don’t think about. But the IEA says we need $2 Trillion to fund the transition. That money needs to come from somewhere. Hence climate fintech comes in to help financial institutions and customers move into more sustainable areas.
All climate projects will require funding large or small. Creating tech to solve this issue will be important.
The report talks about the types of tools that are being used to create these solutions. Although I do wish that the whitepaper when more into technical details of tools mentioned. But I do understand it’s a whitepaper, not PhD thesis.
Blockchain is being used more in climate fintech. Because blockchain tech allows you to verify transactions and contracts digitally without a 3rd party. There is still a lot of froth in the space as people still working out how to use the tech or plain old grifters.
From what I noticed from the report many of the solutions are vertical-based. Meaning a solution will be built for insurance companies in mind or asset management.
I wonder about the various bottlenecks affecting these climate fintechs. Is it collecting data to build these ML models? Or selling these products to would-be customers. The famous product risk vs market risk conundrum.
Stakeholders in climate fintech
The report laid out the ecosystem by mapping various stakeholders into 3 main buckets:
Private capital (Central banks, Investment Banks, Retail and Commercial Banks).
Asset Managers (Assets Managers, Passive funds and Indices, Wealth Managers).
Asset Owners (Insurance companies, Sovereign Wealth Funds, Pension funds).

Your fintech startup will be helping one of these stakeholders. Either helping them invest in climate projects directly or evaluating the assets they already have.
The Other stakeholders don’t directly invest in these climate projects. But help the climate fintech startup. These are Venture capital, individual investors, accelerators, and universities.
The surprising popularity of risk analysis
Risk analysis is an area that found interesting, due amount of active interest in the field. Risk analysis I thought was a solved problem for the climate world and only a small amount of insurance companies will find it useful. But insurance companies plus consultancy have been picking up at an increasing rate.
From the whitepaper:
“Big players are actively acquiring startups. For example, Moody’s recently acquired minor stake in SynTao Green Finance in China and Four Twenty Seven in the US. Major acquisitions were also observed in other regions in both 2019 and 2020; in addition to the previously mentioned MSCI acquisition of Carbon Delta, Bain & Company acquired Ecovadis in Europe, Morningstar acquired Sustainalytics, and BlackRock formed a strategic partnership with Rhodium Group”
In hindsight, it makes sense, as asset owners and insurance companies look to value their assets in a changing world.
The insurance industry is worth $6 trillion, and many other companies need help evaluating their assets with rising sea levels and wildfires. Many houses in California are now worthless as fire strikes that house every year. No insurance company want to cover that.
The risk analysis is built on the rise of satellite imagery and AI. These trends allow companies to collect precise geographic data and model that data into something useful.
Jupiter Intel a company mentioned in the report evaluates climate risk under different temperature scenarios. (i.e. 1.5C vs 2C). By having high-resolution satellite images, they see effects within a few meters. This allows the company to take action to mitigate the climate risk for each of its assets.
Companies like First Street Foundation can use climate models and satellite imagery to put a wildfire risk for each household in the area. Then homebuyers can make their own decisions from there.
The whitepaper mentions that climate risk can be broken down into different areas.
Transition risk: What changes does a net-zero world affect the company?
Policy and Legal Risk, Technology Risk, Market Risk, and Reputation Risk. You can wrap all these into the ESG category. This may explain why consultancies are buying these risk analysis companies.
This is the practice of carbon accounting comes in. Companies will need to reduce their emissions. Going through the supply chain for emissions dealing with multiple risks. Legal risk, following a carbon tax. Reputation Risk, not fulling your very public net zero is an embarrassment.
The other main category is Physical Risk. The risk you think about when it comes to climate risk. What is the likelihood that this house is underwater in 10 years? Or what is the likelihood that this house in turned to ash next summer?
The whitepaper shows the EU taxonomy version of these definitions:
Transition Risk relates to the process of transitioning to a lower-carbon economy
Physical Climate Risk relates to the physical impacts of climate change
Physical climate risk can be bucketed into these areas:

Source: ngfs_physical_climate_risk_assessment.pdf
https://www.ngfs.net/sites/default/files/media/2022/09/02/ngfs_physical_climate_risk_assessment.pdf
You can also think of risk using this equation:
Risk = hazard x exposure x vulnerability
These startups help clients work out all areas of this equation. With simulations and data.
The whitepaper showed this workflow for risk analysis:
Collection >> Processing >> Aggregation >> Solutions.
This workflow is not a unique risk analysis. As this workflow will be used more by many ML-based companies.
I guess that a lot of value is the models, the data less so. Because a lot of value comes from which assets are at risk and what to do about it. Having a dataset of at-risk areas is helpful but a prediction of severity and likelihood is the most useful information for the company. This is where models come in.
Creating an English to Shakespeare Translation AI
This project was supposed to do have a lot more bells and whistles, not just a simple translation model. But as the time investment started getting bigger and bigger. I had to cut my losses.
The model I created translates normal English into Shakespeare English. But the original idea was to generate Eminem lyrics written in a Shakespeare style. A bit much right? 😅
While I may start working on the original features of the project later on. I think it’s a good idea to show the progress I have right now.
Starting The Project First Time Round
The first step I did was working on the Shakespeare translation element. I did a fair amount of googling trying to find projects similar to mine. So I have an idea of what others did for their projects. I eventually found a project which translates Shakespeare English and normal English. The most important part I found was their data. A corpus of various Shakespeare plays in Shakespeare English and normal English.
Now, this is where I drove myself into a ditch. I knew for the translations task I wanted to create an RNN but the code in GitHub was highly outdated. So wanted to find another tutorial that I could use for the model. I was able to find some. But lead to more pre-processing work.
The first step was knowing what type of data I was dealing with. Because the data was not the normal txt file. It took me a while to even work out how to access the file. I was able to access it by converting it into a normal txt file. Little did I know that caused me more problems down the line.
As I was working with a language translation model. I needed the data to be parallel in some type of way. As the words need to match from one list to another list. The problem is when I was doing previews of the text. The text was non-aligned and I was never able to fix it. This pre-processing period added multiple hours to the project. Only to lead to a dead end.
Trying to encode the sequences led to me burning hours of my time. I tried to do it in various ways. Using NLP libraries like Spacy. To using more minor libraries like PyTorch-NLP. To finally following the tutorial’s Keras library. When I eventually found workarounds it led to big memory issues. As it was trying to encode the whole dataset. Even using small batches it still increased pre-processing by a high amount.
The main issues stemmed from me doing a hack job pre-processing the data. Using various libraries conflicting with each other leading to data type errors, memory issues and high pre-processing time. As I wanted to create my model using Pytorch. Using other libraries like Keras was for pre-processing. Not for modelling. But the conflict between half doing the tutorial and my customisations lead to more problems.
A new approach
So, I decided to abandon ship and create a new notebook. Using a new model from a Pytorch tutorial and accessing the files directly without converting them to a text file.
From the previous notebook. I learnt you can access the snt files without converting them into a txt file. Also, I tried using various other language translation code. But led to long pre-processing times, memory issues or long training times.
In the new notebook, I imported all the data files GitHub repo produced. By following the repo’s instructions and updating the code. The pre-processing was a lot more organised as I learnt a few mistakes from the previous notebook. While most of the data files did not get used. It was easier to access the data that I needed and easier to make changes to them.
The processing of the text was aligned correctly. Fixing the main problem of the last notebook.
#Aglined dev and train files
modern_dev_aligned_path = '/content/cloned-repo/cache/all_modern.snt.aligned_dev'
modern_train_aligned_path = '/content/cloned-repo/cache/all_modern.snt.aligned_train'
modern_dev_aligned_file = open(modern_dev_aligned_path, "r")
modern_train_aligned_file = open(modern_train_aligned_path, "r")
content_modern_dev_aligned = modern_dev_aligned_file.read()
content_modern_train_aligned = modern_train_aligned_file.read()
modern_dev_aligned_list = content_modern_dev_aligned.split("\n")
modern_train_aligned_list = content_modern_train_aligned.split("\n")
modern_dev_aligned_file.close()
modern_train_aligned_file.close()
print(modern_dev_aligned_list[:10])
print('\n ----------- \n')
print(modern_train_aligned_list[:10])
['It’s not morning yet.', 'Believe me, love, it was the nightingale.', 'It was the lark,
-----------
['I have half a mind to hit you before you speak again.', 'But if Antony is alive, healthy, friendly with Caesar,#Aglined shak dev and train files
shak_dev_aligned_path = '/content/cloned-repo/cache/all_original.snt.aligned_dev'
shak_train_aligned_path = '/content/cloned-repo/cache/all_original.snt.aligned_train'
shak_dev_aligned_file = open(shak_dev_aligned_path, "r")
shak_train_aligned_file = open(shak_train_aligned_path, "r")
content_shak_dev_aligned = shak_dev_aligned_file.read()
content_shak_train_aligned = shak_train_aligned_file.read()
shak_dev_aligned_list = content_shak_dev_aligned.split("\n")
shak_train_aligned_list = content_shak_train_aligned.split("\n")
shak_dev_aligned_file.close()
shak_train_aligned_file.close()
print(shak_dev_aligned_list[:10])
print('\n ----------- \n')
print(shak_train_aligned_list[:10])
['It is not yet near day.', 'Believe me, love, it was the nightingale.', 'It was the lark, the herald of the morn; No nightingale.' …]
-----------
['I have a mind to strike thee ere thou speak’st.', 'Yet if thou say Antony lives, …]After working out the pre-processing I started implementing the seq2seq model from Pytorch.
While following the Pytorch tutorial, I needed to do a bit more pre-processing of the data. So data can fit into the model. To do that, I needed to make my dataset was in a similar format that the tutorial’s data provides.
Like so:
I am cold. J'ai froid.I turned the separate lists of Shakespeare text and modern text into tuples. So each line of text is paired to its Shakespeare and modern text equivalent. Then I added tab characters in between the entries. To mimic the format of the tutorials data. But that did not work. So I just kept it to tuples which worked fine.
Later I came to set up the model. When I started to run the training function. It gave me an error.

This led to a wormhole of me spending days trying to debug my code. I eventually fixed the various bugs. Which was me not using the filter pairs functions. As it capped the sentences to a max length. Without that, longer sentences were entering the model. This caused errors as the code was designed to take in sentences only of the max length variable.
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p):
return len(p[0].split(' ')) < MAX_LENGTH and \
len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]The only thing I changed was the use of eng_prefixes as it was not relevant to my data. And reduced my dataset to two sentences which was non-usable for training.
After that, I just had to fix a few minor issues plotting charts and saving the weights.
The results after a few attempts:


> You’re making me go off-key.
= Thou bring’st me out of tune.
< What me me here. <EOS>
> Go away!
= Away!
< Away! <EOS>
> Gentlemen, we won’t stay here and anger you further.
= Gentlemen both, we will not wake your patience.
< Tis we will not not you your <EOS>
> A little bit.
= A little, by your favor.
< A good or <EOS>
> You were right the first time.
= You touched my vein at first.
< You do the the the <EOS>
> Where are these lads?
= Where are these lads?
< Where are these these <EOS>
> You’ve heard something you shouldn’t have.
= You have known what you should not.
< You have said you have you true. <EOS>
> Or else mismatched in terms of years;— Oh spite!
= Or else misgraffed in respect of years— O spite!
< Or is a dead, of of of <EOS>
> Oh why, nature, did you make lions?
= O wherefore, Nature, didst thou lions frame?
< O wherefore, Nature, didst thou didst <EOS>
> Come down, look no more.
= Come down, behold no more.
< Come weep no more. <EOS>
input = I go to work.
output = I go to your <EOS>
The results of this model have a lot to be desired. But I’m happy to get a working model up and running. I can improve the results even more by increasing iterations and increasing the data sent to the model. The Google Colab GPU allows me to get a decent amount of training done. But there is a bug which states runtime has stopped while the model is still training. Luckily the runtime comes back after training. But I don’t know the times the runtime does not come back, therefore, cutting off my training.
Find this Project Interesting?
Get project updates and ML insights straight to your inbox
So I can make the project slightly more visual. I created a Streamlit app where the user can input text and the translation will be returned. I honestly wanted it to look like google translate. But I don’t know how to do that.
I had to find a good example of a translation project. As I never used Streamlit before. I was able to find this repo. I used this as the basis for my Streamlit app.
I first needed to load this repo to launch its Streamlit app. So I can get a feel on how the Streamlit app works so I will have an idea how to edit the repo for my model.
Loading the Streamlit app took a lot of work. Because Streamlit did not install in my local machine in the beginning. So I opted to use Google Colab. But because Streamlit works by routing via localhost. Which I can’t do directly using Google Colab. I had to find a way to host local addresses inside Google Colab.
I found this medium article. Which suggested I used the Ngrok service to create a tunnel to route the streamlit local address to a public URL.
After a bit of fiddling around, I was able to run the app. The only problem is that python started giving me errors in Streamlit. Which looked like this:
After a few fixes I was able to get the repo’s Streamlit app running:

Now I had to replace the repo’s TensorFlow model with my Pytorch model. I knew this was going to be a daunting task. And I was proved right. As I was hit with numerous errors and roadblocks when setting it up.
One of the most time-consuming tasks was loading objects I had from the notebook into the Streamlit app. As I had pickled objects this lead to errors because it was from the __main__ namespace. So I had to create a custom unpickler class.
Loading the model was easier and I was able to test it on my local machine first. Loading the model on the Google Colab version led to some issues but I was able to fix them. As these were minor issues like incorrect paths to the objects and model and making sure the model loaded on a CPU device rather than a GPU device.
Afterwards, I was able to get some results:

Later on, I added a random pairs button that would show multiple examples in one go:

Adding the random pairs feature took a bit of adjusting. As multiple errors came up with the decoding of the text.
After I fixed the encoding issues I moved on to implementing the attention matrices.

Conclusion
I mentioned this at the beginning of the blog post. This project had a much bigger scope. But had to be cut. So, I may implement the second part of this project later on. Which was generating Eminem lines and feeding them into the Shakespeare translation model.
After this project, I want to do a lot more reading about RNNs. Because I don’t think my knowledge is up to scruff. So I would do various things like implementing RNNs using NumPy. Implementing some RNN related papers. And learning the maths required to understand the topic. Hopefully taking these actions should improve my understanding of RNNs and deep learning in general.
If you found this article interesting, then check out my mailing list. Where I write more stuff like this
4 ML Roadmaps to Help You Find Useful Resources To Learn From
There are lots of ML resources around. But so much material how do you pick which ones are good and right for your situation?
These are what roadmaps are for. Many people in the ML community have made some you can view.
One of the most comprehensive ML roadmaps I have seen. Most beginner to intermediate questions will likely be answered in this mind map.
Deep Learning Papers Reading Roadmap
A great list of papers that you can try to implement. That starts from the fundamentals of deep learning to the state of the art.
Deep Learning's Most Important Ideas - A Brief Historical Review
It is not formally a roadmap. But can be used as such. As it talks about the most fundamental papers of DL. That you can implement.
A machine learning roadmap by Santiago
Short article giving a high level run down on learning ML. And the various resources.
This is a very short article but hopefully, you found some of the resources useful.
-
If you found this article interesting, then check out my mailing list. Where I write more stuff like this
How To Scrape A Website For Your ML Project
A while ago, I was reading a thread on the LearnML subreddit. Which the OP needed to scrape webpage data for his ML project.
People in the thread gave good answers. Which was mainly learn how to use beautifulsoup and selenium.
But the OP may not know how to relate to his ML project. If he has no experience with those libraries
I have used BeautifulSoup and Selenium for some of my data science projects. While not the most advanced tasks it got the work done.
https://www.tobiolabode.com/blog/2020/4/21/bookstores-vs-income-data-science-project-part-1
https://www.tobiolabode.com/blog/2020/4/26/bookstore-vs-income-part-2
In this blog post, I’m going to show you how to scrape a webpage with some useful data and convert it into a pandas dataframe.
The reason why we want to convert it into a dataframe. Is that most ML libraries can handle pandas data frames and can be edited for your model with minimal changes.
First, we are going to find a table on Wikipedia to convert into a dataframe.
Here I’m going to scrape a table of the most viewed sportspeople on Wikipedia.

First, a lot of work will be navigating the HTML tree to get to the table we want.

We will use BeautifulSoup with the help of requests and the regex library.
from bs4 import BeautifulSoup
import requests
import re
import pandas as pdHere we are extracting the HTML code from the webpage:
website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').textsoup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())</a>
</li>
<li id="footer-places-disclaimer">
<a href="/wiki/Wikipedia:General_disclaimer" title="Wikipedia:General disclaimer">
Disclaimers
</a>
</li>
<li id="footer-places-contact">
<a href="//en.wikipedia.org/wiki/Wikipedia:Contact_us">
Contact Wikipedia
</a>
</li>
<li id="footer-places-mobileview">
<a class="noprint stopMobileRedirectTog
`We want to collect all of the tables from the corpus. So we have a smaller surface area to search from.
wiki_tables = soup.find_all('table', class_='wikitable')
wiki_tablesAs there are numerous tables we need a way to filter them.
We know that Cristiano Ronaldo has an anchor tag that will likely be unique to a few tables.

We can filter those tables that have an anchor tag with the text Cristiano Ronaldo. While finding some parent elements that contain the anchor tag.
links = []
for table in wiki_tables:
_table = table.find('a', string=re.compile('Cristiano Ronaldo'))
if not _table:
continue
print(_table)
_parent = _table.parent
print(_parent)
links.append(_parent)<a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a>
<td style="text-align: left;"><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a>
</td>
<a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a>
<td style="text-align: left;"><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a>
</td>
<a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a>
<td style="text-align: left;"><a href="/wiki/Cristiano_Ronaldo" title="Cristiano Ronaldo">Cristiano Ronaldo</a>
</td>The parent only shows us the cell. We need to climb higher up the tree.
Here is a cell with the browser web dev tools.

parent_lst = []
for anchor in links:
_ = anchor.find_parents('tbody')
print(_)
parent_lst.append(_)By using the tbody we able to return other tables that would contain the anchor tags from earlier.
To filter even more we can search through the various headers of those tables:
for i in parent_lst:
print(i[0].find('tr'))tr>
<th>Rank*</th>
<th>Page</th>
<th>Views in millions
</th></tr>
<tr>
<th>Rank</th>
<th>Page</th>
<th>Views in millions
</th></tr>
<tr>
<th>Rank</th>
<th>Page</th>
<th>Sport</th>
<th>Views in millions
</th></tr>The third one looks like the table that we want.
Now we start to create the logic needed to extract and clean the details we want.
sports_table = parent_lst[2]
complete_row = []
for i in sports_table:
rows = i.find_all('tr')
print('\n--------row--------\n')
print(rows)
for row in rows:
cells = row.find_all('td')
print('\n-------cells--------\n')
print(cells)
if not cells:
continue
rank = cells[0].text.strip('\n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('\n')
print('\n-------CLEAN--------\n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])
for i in complete_row:
print(i)To break it down:
sports_table = parent_lst[2]
complete_row = []Here we select the 3rd element from the list from earlier. As it’s the table we wanted.
Then we create an empty list that would store the details of each row. As we iterate through the table.
We create an loop that would iterate each row in the table and save them into the rows variable.
for i in sports_table:
rows = i.find_all('tr')
print('\n--------row--------\n')
print(rows)
for row in rows:
cells = row.find_all('td')
print('\n-------cells--------\n')
print(cells)We create a nested loop. That iterates through each row saved from the last loop. When iterating through the cells we save the individual cells in a new variable.

if not cells:
continueThis short snippet of code allows us to avoid empty cells and prevent errors when extracting the text from the cell.
rank = cells[0].text.strip('\n')
page_name = cells[1].find('a').text
sport = cells[2].find('a').text
views = cells[3].text.strip('\n')Here we clean out the various cells into plain text form. The cleaned values are saved the variables under the name of their columns.
print('\n-------CLEAN--------\n')
print(rank)
print(page_name)
print(sport)
print(views)
complete_row.append([rank, page_name, sport, views])Here we add the values into the row list. And print the cleaned values.
-------cells--------
[<td>13
</td>, <td style="text-align: left;"><a href="/wiki/Conor_McGregor" title="Conor McGregor">Conor McGregor</a>
</td>, <td><a href="/wiki/Mixed_martial_arts" title="Mixed martial arts">Mixed martial arts</a>
</td>, <td>43
</td>]
-------CLEAN--------
13
Conor McGregor
Mixed martial arts
43Now we convert it into a dataframe:
headers = ['Rank', 'Name', 'Sport', 'Views Mil']
df = pd.DataFrame(complete_row, columns=headers)
df
Now we have a pandas dataframe you can use for your ML project. You can use your favourite library to fit a model onto the data.
--
If you found this article interesting, then check out my mailing list. Where I write more stuff like this
Making Sure All Your Data Sources End Up in The Same Shape
I was reading a thread a while ago and the OP asked:
I have data from different input sources that vary in the number of columns they have. It looks like for Keras I need to make sure every file has the same number of columns. My first thought is to just add 0's where the columns should be but I don't know what this does to weighting so I'm asking here. Thanks!
This looks like another feature engineering problem. My best answer is to make a combined dataset of these various sources.
This can be done with pandas. Using the concatenate function and merge functions.

result = pd.concat([df1, df4], axis=1)An example from the pandas documentation.
Another example from the documentation:

result = pd.concat([df1, df4], ignore_index=True, sort=False)To get rid of the NaN rows. You use the DropNA function or while concatenating the data frames use the inner attribute.
Check out the pandas documentation here.
A person in the thread recommended a decent course of action:
it might be the best to manually prepare the data to use only/mostly the columns which are present across all datasets, and make sure they match together.
This is a good idea. But they may be important features that may be dropped in the process. Because of that, I would recommend the first option. Then deciding which columns to drop after training. Depending on your data you may want to add extra features yourself mentioning the input source.
The main task to do is some extra pre-processing of your data. Combining them is the best bet. From there you can apply various feature selection techniques to decide which columns you would like to keep. Check out the pandas documentation if you not sure how to deal with Dataframes.
If you found this article interesting, then check out my mailing list. Where I write more stuff like this
Using ARIMA to Forecast Your Weekly Dataset
I was reading a Reddit thread in which the OP called for help forecasting some of the weekday performance in the dataset. Machine learning allows you a few ways to do this.
This is the area of time series forecasting. There are two main ways to do this. First, you can use neural networks like LSTMs. Which takes a sequence of data and predicts the next time window. The second is to use the methods from the stats world. Mainly stuff like ARIMA.
In this article, we are just going to focus on using ARIMA. A technique used in the stats world for forecasting.
Because ARIMA is easier to set up and understand compared to a neural network. Also, very useful if you have a small dataset.
One of my projects was to forecast rainfall in a certain area. It did not work well as I hoped. But it will likely work better if you have a clear correlation between variables.
A person in the thread gave a good resource for ARIMA. https://www.askpython.com/python/examples/arima-model-demonstration
Cause I’m not an expert in time series forecasting I can give you some resources you check out.
https://machinelearningmastery.com/arima-for-time-series-forecasting-with-python/
https://www.machinelearningplus.com/time-series/arima-model-time-series-forecasting-python/
Some general tasks you want to do:
- Make sure your data is stationary
- Install pmaria
- If your data is seasonal use SARIMA instead.
After using the resources above, you then forecast the win-loss ratio for your dataset or any other variable you want to forecast in the future.
If you found this article interesting, then check out my mailing list. Where I write more stuff like this
Some YouTube channels that review papers
When I was reading a Reddit thread. People were wondering if there were YouTubers reviewing papers. As the OP noticed that one of the YouTuber's that he regularly watched stopped uploading videos. There are a few YouTubers that talk about ML and review papers.
I decided to compile some of the YouTube channels into this short list.
Two Minute Papers does great overviews of fascinating papers. Showing the increasing progress of ML.
Some of the videos I liked:
- 4 Experiments Where the AI Outsmarted Its Creators
This video showed various AI solving a problem not in the way the researchers intended to. That may include abusing the physics in the simulation or lateral thinking used by the model.
- A Video Game That Looks Like Reality!
A review of a paper that takes GTA V gameplay and converts them to photo-realistic footage.
Yannic Kilcher does in-depth reviews of various papers. As you go through the paper he shows you his thought process. And showing what important inside the paper. Very useful if don’t read that many papers. (Like me)
Some good videos:
A review of a paper that introduced transformers.
- DeepMind's AlphaFold 2 Explained! AI Breakthrough in Protein Folding What we know (& what we don't)
A great rundown on protein folding and speculating how Alphafold 2 works.
- GPT-3: Language Models are Few-Shot Learners (Paper Explained)
A comprehensive paper reading of the GPT-3 paper.
Bycloud you may have seen him around on Reddit. Creates short and insightful summaries of papers.
- AI Sky Replacement with SkyAR
Summary of paper that creates AR effects in video footage. Adding various effects to the video footage’s sky.
- AI Generates Cartoon Characters In Real Life [Pixel2Style2Pixel]
Reviewing a paper that converts cartoon characters to real-life equivalents and vice versa. Also explains how the paper made it easier to adjust the parameters of the GAN. Helping us adjust what images we want to produce.
This is a podcast series that interviews top ML researchers. While they don’t have videos about papers alone. As they interview various experts in the field. So they talk about many papers as a consequence.
While this is a short list maybe you can find these channels interesting and learn something new.
-
If you found this post useful, then check out my mailing list where I write more stuff like this.