This is a continuation of the Evernote scraper.
Now the main goals for this stage turning the elements from the div tag into a useable list, so it can be turned into useful data format later on. With the for loop which iterates over div tags content. Using this loop to save the contents in a list. When I was trying to develop a loop which would remove HTML items from the list I noticed that items in the were BeautifulSoup objects.

So made a new loop which iterated over the list a turned the items into string objects. The items which were turned into strings are sent into a new list.
sibling_contents_string = []
for item in sibling_contents:
item = str(item)
sibling_contents_string.append(item)
Now I just need to get rid of the </br> items by matching the stings in an if else statement. But trying use the simple if else statement it did not work.
for item in sibling_contents_string:
if item == '</br>' or '<br/>':
sibling_contents_string.remove(item)
But I was able to make other if else using regex. Using this pattern: <.br>|<br.> this was able to purge all of the html tags. Using list compression which reduce the need for more lines:
regex = re.compile(r'<.br>|<br.>')
somelist = [item for item in sibling_contents_string if not regex.match(item)]
After I need to work out how to get rid of the first few elements of the list. As they are not needed data for the project. I will simply slice the list. I found that by slicing the by [8:] I was able to get rid of the non-needed elements. Now this sliced list can be stored in another variable as it can be used later.
Now I need to filter out the items into the dates and lifts. I will be utilising the regex again. Using the search function on the command prompt I looked at the values to see if any exception that needs to look out for. So when I develop the regex pattern it will be accounted for.
I developed variables to store the regex patterns of the different values:
regex_dates = re.compile(r'(Jan(uary)?|Feb(ruary)?|Mar(ch)?|Apr(il)?|May|Jun(e)?|Jul(y)?|Aug(ust)?|Sep(tember)?|Oct(ober)?|Nov(ember)?|Dec(ember)?)')
regex_squat = re.compile(r'(Sq).*|(sq).*')
regex_press = re.compile(r'.*(Pr).*|.*(pr).*')
regex_deadlift = re.compile(r'.*(d?ead).*')
regex_bench = re.compile(r'.*(B?ench).*')
regex_power_clean = re.compile(r'.*(P?ower).*')
regex_other_html = re.compile(r'<[^>]*>')Now the next stage is to use to regex to filter the values into different columns of a csv file. Eailer I made a rough draft(in a text file) of how I would like the file to look like.

First using the regex patterns I was able to extract the values into different lists. Using list compression:
Dateslist = [date for date in sibling_contents_clean if regex_dates.match(date)]Printing the newly made dateslist variable gave me this:

So the list compression did a good job extracting the values. So did this for all the values I want to turn into columns. After making the lists I noticed that many of the values in the lifts had notes. So decided I wanted to copy them into a separate list so I can use it for a new notes section of the csv file.
I opted to keep stings that are over 25 characters as most normal items where around 15-20 and comments are more than 25 characters. Using the len function I was able to return items with more than 25 characters:

In plain text to make it more clear:

It was able to extract all of the notes but I noticed it also extracted items which did not have any notes. The issue is that some of the items had lots of emojis which made the value have more than 25 characters. The fix I found is to do another regex match to exclude it from the new list. Using this regex pattern to find an item that had ticks: re.compile(r'.*(✔️)') I saved it in a variable and used it in the loop.
Notes_squat_list = []
for squat in list_squat:
if len(squat) > 25:
if not regex_ticks.match(squat):
Notes_squat_list.append(squat)Items that have crosses are added straight to the lists regardless if they have ticks or not. Then items that don’t have crosses but have ticks are excluded from added to the lists. Because of the new if statement the list compression does not work anymore. As if statements in list compressions work as nested if statements, not if statements on the same level.
After getting the list ready I noticed a major issue when stitching them up. When I used the zip function to merge the dates and squat list, it worked perfectly well. The issue came when adding the other lists.
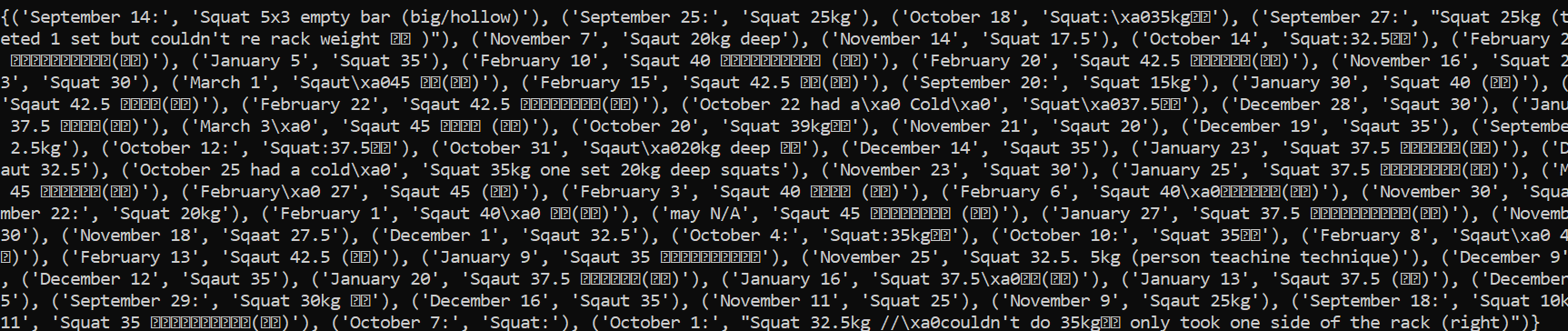
As you can see here the values aligned correctly with the correct dates. But the other values are attached to the wrong dates. This is because the lifts alternate on different days. Compared to squats which do not change.
So I opted for a more simple solution which would take every 4th value in the list. This done as the format goes like:
September 15
Squat 29kg
Press 5kg
Power clean 10kg
threelist = [sibling_contents_clean[i:i+4] for i in range(0,
len(sibling_contents_clean), 4)]Adapted the code from a stack overflow answer, it works well for a few values but the order starts to get jumbled up so the date is not first. So most of the list(this is a nested list) is incorrect.

I was able to develop a loop which would shift the list to the next value if it was it was not a date:
while i < len(sibling_contents_clean):
if regex_dates.search(sibling_contents_clean[i]):
threelist2.append(sibling_contents_clean[i:i+4])
print(f"correct, {sibling_contents_clean[i]}")
else:
print(f"incorrect, {sibling_contents_clean[i]}")
lenoflist = len(threelist2)
print(lenoflist)
threelist2[lenoflist-1].append(sibling_contents_clean[i:i+1])
threelist2.append(sibling_contents_clean[i+1:i+5])
i += 1
i += 4This was able to improve the list with more correct values.

But they were still more value to correct.
Before making the loop I had to use the python debugger to work out what was wrong. I decided to print values that stated if they were incorrect or correct using the if else regex statement which gave an idea of how much values I had to fix.

After that using the python debugger was able to run the program line by line. And worked out the value of the sibling_contents_clean[i] and the i variable.

By changing the I variable manually was able to work when the loop was going to print out an incorrect list of values. I learned to shift the list by one place I needed to +1 to the start and end of the list. For example sibling_contents_clean[i:i+4] prints out the number of i to 3 more places. If looked like I looked like this sibling_contents_clean[0:0+4] it will start to the first value to the third. After I was able to use the slice notation correctly to print out the stuff I want. But they are still issues.
Later I amended to else statement to elif statement. The condition for the elif statement if the value matches with any of the lift regex(squat, deadlift etc.) that will append to the previously made string. This was done as non-lift values were being appended to the back some of the list but they were not needed. The else statement to focus on mainly the non-lift and non-date values. The else statement simply separates the value to a single list. For example:

Now the while loop with the if statements looks like this:
while i < len(sibling_contents_clean):
if regex_dates.search(sibling_contents_clean[i]):
threelist2.append(sibling_contents_clean[i:i+4])
print(f"correct, {sibling_contents_clean[i]}")
elif master_regex.search(sibling_contents_clean[i]):
print(f"incorrect, {sibling_contents_clean[i]}")
lenoflist = len(threelist2)
print(f' length of list: {lenoflist}')
threelist2[lenoflist-1].append(sibling_contents_clean[i:i+1])
threelist2.append(sibling_contents_clean[i+1:i+5])
i += 1
else:
print(f"incorrect, non-lift, {sibling_contents_clean[i]}")
threelist2.append(sibling_contents_clean[i:i+1])
i += 1
i += 4The master regex is simply all the regex patterns of the lifts with added | between them. And also ?: attached to the capturing groups.