Web Scraping laptops prices with BeautifulSoup
Recently I’ve been learning a new technology which is BeautifulSoup. A python module used for web scraping. So over the past days doing some tutorials and watching videos about web-scraping. I decided to choose BeautifulSoup it was the most used module used for the tutorials and videos that I saw. The first main tutorial I did was from the website realpython which gave a pretty good overview of web-scaping and also the requests library. In that tutorial, I had to scrape Wikipedia’s XTools to found out the most popular mathematicians on Wikipedia. A very odd project idea, I know. But was effective for getting me to the basics of the libraries. As had knowledge of HTML, it helped speed up the process of learning.
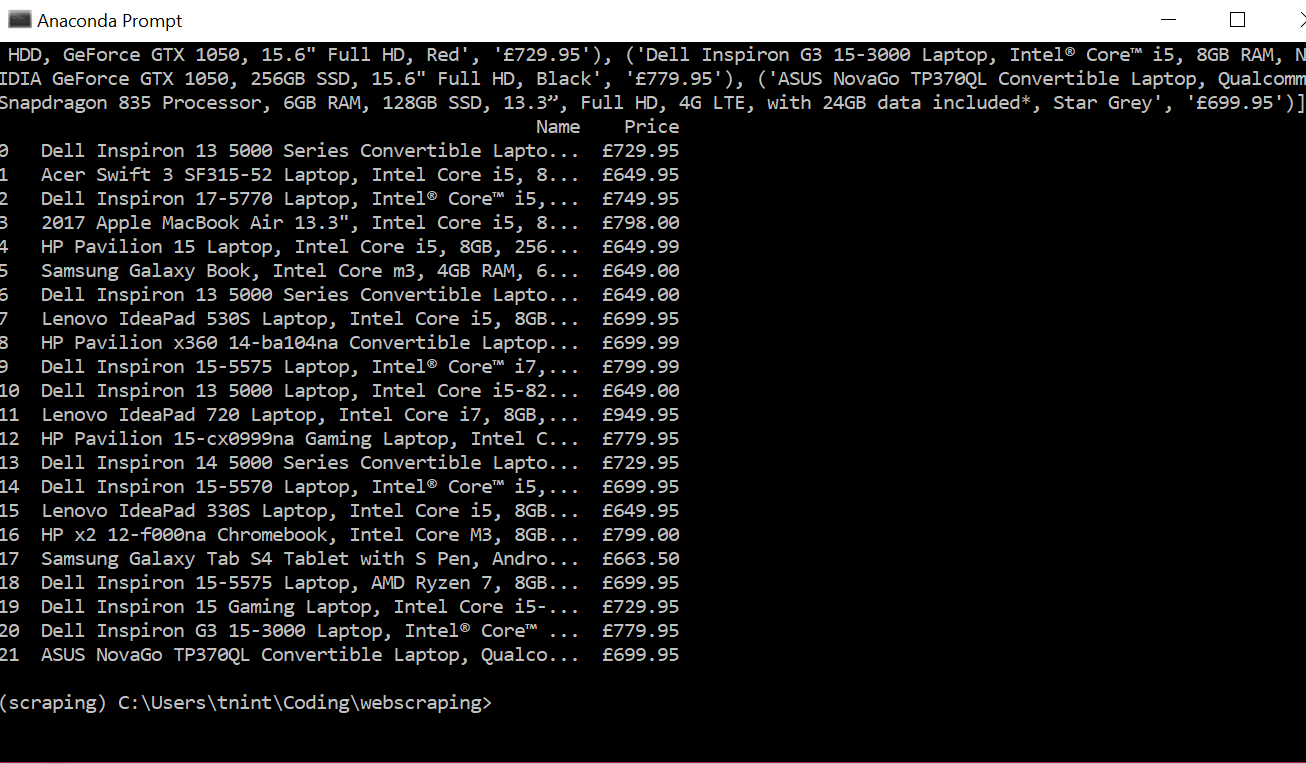
To test my skills decided to make a mini-project for myself where scrape prices for laptops. The reason why for this project I’m looking for new laptops so this project will prove helpful for my research. To start decided to used a different tutorial for my code from hackernoon.
from bs4 import BeautifulSoupimport requestsimport pandas as pdpage_link = "https://www.johnlewis.com/browse/electricals/laptops-macbooks/view-all-laptops-macbooks/price=600-800/_/N-a8fZ6lq8?showInStockOnly=false&sortBy=rating"#fetch content from urlpage_response = requests.get(page_link, timeout=5)# parse htmlpage_content = BeautifulSoup(page_response.content, "html.parser")The code was short and simple but unlike the code from the realpython tutorial did not have functions did catch errors from requests or use the functions to make the program more abstract but still readable. The goal of the solution is to extract the name of the laptop and the price, A very simple goal. Using the code from the hackernoon tutorial I noticed when printing the statements that it only printed HTML not the just the text. To fix this found another tutorial on youtube with showed to extract text from an HTML element. Sometimes the beautifulsoup functions are similar but do slightly different things, For example, find()vs find_all()the first only find one instance of the HTML element the second finds all as a list. After that using a for loop with the find_all() function helps extract the text of the laptop names and prices. I printed the text and appended them as a tuple to a list called records. Next using the pandas library I converted the list to a data frame which I then exported to an exported to a CSV for later use.
The project did not take to long and the code only ran up to 28 lines which surprised me. I think to show how much the requests and beautifulsoup libraries abstracted most of the complicated work away. Also helps I only extracted one page. In future projects may use something like selenium for non-static websites or use it to navigate multipage.