How to convert non-stationary data into stationary for ARIMA model with python
If you’re dealing with any time series data. Then you may have heard of ARIMA. It may be the model you are trying to use right now to forecast your data. To use ARIMA (so any other forecasting model) you need to use stationary data.
What is non-stationary data?
Non-stationary simply means that your data has seasonal and trends effects. Which change the mean and variance. Which will affect the forecasting of the model. As consistency is important when using models. If the data has trends or seasonal effects then the data is less consistent. Which will affect the accuracy of the model.
Example dataset
Here is an example of some time series data:

This is the number of air passengers each month. In the United Kingdom. You can fetch the data here. From 2009 to 2019.
As we can see the data has strong seasonality. As people start to go on their summer holidays. And a tiny bump in the winter. To avoid the cold. If you like to use a forecasting model, then you need to change this into stationary data.
Differencing
Differencing is a popular method used to get rid of seasonality and trends. This is done by subtracting the current observation with the previous observation.
Assuming you are using pandas:
df_diff = df.diff().diff(12).dropna()This short line should do the job. Just make sure that your date is the index. If not you will get a few issues plotting the graph.
If you still want to keep your traditional index then simply create a new dataframe. Keeping the columns separated and shifting your numerical column.
diff_v2 = df['Passengers'].diff().diff(12).dropna()time_series = df['TIME']
df_diff_v2 = pd.concat([time_series, diff_v2], axis=1).reset_index().dropna()The concatenation produces NaN values. As the passengers series is shifted ahead compared to the time series. We use the dropna() function. To drop those rows.
df_diff_v2 = df_diff_v2.drop(columns=['index'])
ax = df_diff_v2.plot(x='TIME')ax.yaxis.set_major_formatter(mpl.ticker.StrMethodFormatter('{x:,.0f}'))This is here as we are dealing with large tick values. This is not need if your values are less than thousand.
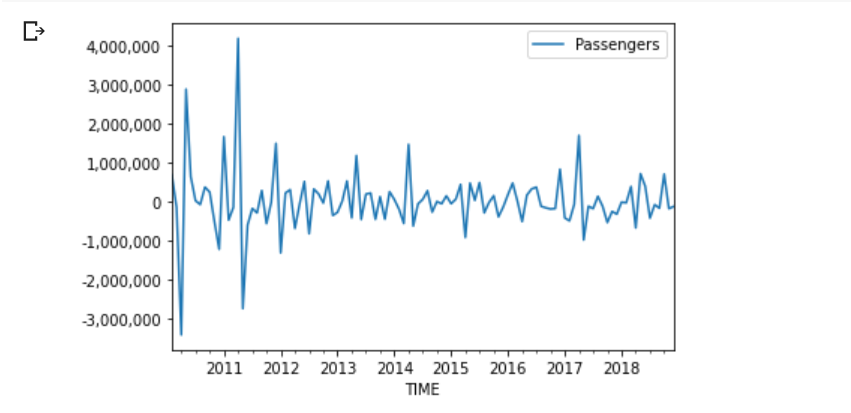
Now your data can be used for your ARIMA model.
If you found this tutorial helpful, then. Check out the rest of the website. And sign up to my mailing list. To get more blog posts like this. And short essays relating to technology.
Resources:
https://www.quora.com/What-are-stationary-and-non-stationary-series
https://www.analyticsvidhya.com/blog/2018/09/non-stationary-time-series-python/
https://machinelearningmastery.com/remove-trends-seasonality-difference-transform-python/
https://towardsdatascience.com/hands-on-time-series-forecasting-with-python-d4cdcabf8aac
Improve accuracy when adding new data to machine learning model
ML model having recall of .97 and precision of 93 and accuracy of 95 on test data but in completely new data it doesn't give good results. What could be the possible reason? – From Reddit
I have seen this too many times. Your model looks perfect with high scores. And somewhat low inference time. But you add new data to test how it would fair. But the results a negligible at best. So you start to wonder what’s wrong with my model. Or maybe it’s my data.
This is a case of overfitting. When the model overly learns the data from its training phase.
To fix this. You want to make sure your data is set up correctly. So make your dataset split into testing data and training data. And depending on your preference add a validation set as well.
Now start training your model using the training data. Which should learn enough to develop a general pattern of the data.
Now check using test data. If your test data is good, then half of the problem is solved. You then want to use the validation dataset to help tune your hyperparameters.
If the new data is giving poor results. Then you may want to find any mistakes in the model or data.
First things first. Simplify your model. Find the simplest model that can deal with your problem.
Second, turn off any extra features like batch normalization or dropout
Third, verify your input data is correct
On a separate note. Make sure your new data you're adding to model is correct as well. Sometimes we can do minor mistakes like forgetting to do pre-processing correctly when using a separate piece of data.
Doing this should remove any bits of your model that are adversely affecting your results. Checking the input data and the test data. Is a simple double-check. As an error in the data can go unnoticed. And maybe affecting your model. Doing this gives you are a chance to spot any of those errors.
Hopefully by doing many of the steps above. The issue should be fixed. If not go to the article I linked above. And go through all the steps in that article.
How to find similar words in your excel table or database
I was reading a post about a person who has a problem mapping data from an excel table to the database. You maybe find it tedious to transfer data between the “cats” fields to the “cat” field.
While I'm not an expert in NLP at all. From googling around it can somewhat be done.
First, you want to move your words you have into a separate text file.
If you have past data put them into two separate files. For original data and destination data.
For example:
original data: mDepthTo
destination data: Depth_To
For pre-processing. After that, you want to remove ASCII or miscellaneous characters. And punctuation. So, you want to get rid of a couple of those underscores. To make life easier for yourself turn the data into a uniform case. The NLTK library is good at this.
Then after that, you want to encode those words into vectors. Try TF-IDF. Again, you can use it with SK-learn. So, you don’t need to install any extra modules.
A brief explanation of TF-IDF
TF-IDF is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. This is done by multiplying two metrics: how many times a word appears in a document, and the inverse document frequency of the word across a set of documents https://monkeylearn.com/blog/what-is-tf-idf/
Now we want to work out the similarity between the vectors. You can use concise similarity as that’s the most common technique. Again, sklearn has this so you can try to out easily.
Cosine similarity is a metric used to measure how similar the documents are irrespective of their size. Mathematically, it measures the cosine of the angle between two vectors projected in a multi-dimensional space.
Now we make some progress on word similarity. As you can compare both words in your text files.
For testing, you may want to save some examples. So, you can use for evaluation of the NLP model. Maybe you can create a custom metric for yourself about how closely the model was able to match the destination data.
Most of the ideas came from this medium article. Just tried to adapt it to your problem
You should check it out. They know what they are talking about when it comes to NLP.
Summary:
1. Save data into separate text files
2. Pre-process the data. (Punctuation, odd characters etc)
3. Encode data with TF-IDF
4. Get word similarity with Cosine similarity
5. Create metric to use. To see if the model maps data correctly.
Why my next topic I will be learning is ML-ops
While I'm still developing my neural transfer project. A skill that I'm lacking very dearly is publishing models and projects. I have released other projects but they are not ML projects. So I want to make a project in the near future. Where I can collect data from the user can improve the product. A lot of skills regarding implementing deep learning models. Are not advertised that much. They some course that I'm thinking to learn from. Full-stack deep learning. And a YouTube course on Papers with code. But learning some continuous integration and continuous deployment skills will be nice. While notebooks are great. They are only accessible to fellow nerds. If I want to share my work with the wider public then sharing them via a website or app may be better.
ML-ops is a new field. Which probably explains why it hasn’t been getting much attention. Only until recently. I guess there is a critical mass of people that can make decent models. But starting to learn that implementing those models in real life is a bit of a pain. SO they want to learn how to deploy those models more effectively. For me, I'm still learning how to create a good model consistently. While I don’t think I'm bad. I'm not sure if I can hold it on my own. I don’t know it may be some type of impostor syndrome. As when I make models I was using a template from somewhere. Like example code from a Pytorch tutorial. While I mostly know what’s going on. Sometimes I'm a bit lost. I think the answer like Jeremy Howard says is to train more models.
While this issue should go away soon. I haven’t been spending more time on my projects. Meaning that is less time to iterate and learn. I need to increase the iteration process. Of my learning. Meaning I want to be creating more models. Right now its probably one personal project a month. Again a lot of university work. Has slowed me down. But major deadlines have passed. So I should have more time for my projects.
For ML-ops, I guess I will be using things like Github-actions. Which is a tool I tend to see a lot. When people showing a few screenshots on Twitter. I guess they are other tools that I don’t know about. I think deep learning education online is still weighted towards the research side. Which is fine if you want to do research. And a lot of research is very interesting. But they are less focus on implementing and deploying those models. I think I wrote a blog post about this a while back. Where I want to focus more on deploying products. Which I did not do for the green tea and oolong tea classifier. But should do with future projects.
ML-ops may be an important skill for me to learn. If I want to start making software I want to sell in the near future. It is unlikely to be a SasS product. Due to the fact, sass products take a lot of time and energy. And most importantly I have no experience selling products online. So it is better to get that experience on my belt first before I do anything crazy. This product could be a small ML model that people can pay a small fee to use. I don’t know. Right now I'm just thinking out loud.
While learning deep learning is cool. If I do want to show my wares. Then they should be accessible for non-technical people. A lot of the projects that go viral tend to be highly visual like toonify. And/or an easy way to play with the model. Like a website or app. This is not a real person.com was a website that produced fake people from GANs. Or the user had to do was refresh the webpage. Then a new fake person appeared. If the knowledge was stored in a notebook only a few people can access it. Even worst a research paper. Where a very small amount of people can understand and compared what's going on.
A lot of problems when it comes to me learning deep learning. Is simply increasing my output. I just need to pump out for stuff. Pytorch has allowed me to finish projects easier. But I still need to do more work.
ML-Ops is a topic I don’t think I can just read up. So it's likely I will need to apply them to many of the projects, that I will be working on in the future. Can't imagine me using some MNIST dataset and deploying that to Github. ML-Ops frankly is used for real deep learning projects. I don’t know how long learning the topic will take. But I will be happy to add that skill into my arsenal. As that means I can deploy ML models to the web. In good condition. With users even adding feedback to the model. That can be the backbone of many great products in the future.
Or maybe. I just get distracted again and start learning about a new topic. To be honest, AR is looking very interesting right now. So I may work on that pretty soon.
The Uses and Need for Interpretable AI
A popular topic in the deep learning research space is interpretable AI. Which means AI that you can understand why it made a decision. This is a growing field as AI is creeping into lots of industries. And accuracy is not just important but the method or reasoning of the decision is important as well. This is important were the consequences of the decision is very critical like medical and law. In a Wired article, they highlighted this when the AI was flagging patients to check up. Which the doctors have no clue why the AI did that. So some doctors took it upon themselves to learn some stuff about the AI. To guess what it was thinking when it decided. Not having reasoning for the AI lead to some disagreements between the nurses and doctors. So having an explainable AI would help in that scenario.
Interpretable AI can help discover bias in the AI. When AI was used in the criminal law realm. Lots of AI tended to make harsher judgements of black people compared to white people. Having an explainable AI would have made it much clearer that the AI was being driven by the race of a person. Explainable AI can give us peace of mind if done correctly. As it can list the variables that affected the sentence of the person. Instead of a black box-like now where it just spits out a number. It could tell why it spat out the number.
I'm going, to be frank. I only have a surface-level understanding of the topic. I only read one or two light papers. So more reading will be needed. And also implementation. But I think interpretable AI can be very useful for many AI systems like I explained above.
One video I watched. Said her and her team used interpretable models to debug models. And was able to increase the accuracy of the model significantly. So we can be able to do stuff like that. Debugging deep learning models is hard. Due to the black-box nature of them. An interpretable model can help us shine the light on these models. Helping us improve our models even more. In an unreleased post, I wrote about interpretable AI can help make recommendation systems used by the major tech companies more transparent. Also leading to more understanding by users and other stakeholders like the regulators. This can help people identify harmful rabbit holes like conspiracy videos and anti-vax content.
By having a better understanding of why a tech service is recommending you stuff. The user can take action towards changing the situation or keeping it like it is. Maybe using that information the tech company can add features to stop a user from falling too deep in an echo chamber. Like adjusting the suggested videos to more moderate content. Or videos that have different views than the echo chamber that the user is in. Or maybe have nudges saying, “you been watching the same type of videos for a while, try something else.”
Also, it can help identify videos that are going viral in certain areas. Especially if the area is problematic. So, if you can see a video in conspiracy theory land. Gaining traction, you can see how and why the algorithm is recommending the video. From there the tech company can make the decision to do a circuit breaker with the video. Or let it run its course.[1] This may be better than trying to outright ban topics on your service. Due to the whack a mole effect.
Obviously, almost all of this is automated. So the insights are taken from the interpretable AI. Will need to be transferred into another system. And be factored into the model. I don’t know how would one implement that though.
An explainable AI can help moderation teams for tech companies. As an AI can help tell the moderators why it decided to ban a piece of content. And if its an appeal then the moderator can explain to the user why he was accidentally banned. And explain to the user how to avoid it from happening again. Also, the moderator can help tell the AI that it was wrong. So the AI can get better at its job next time around.
When YouTube videos get removed from the platform. YouTube does not tend to offer a good explanation of why it was so. It normally gives some PR / Legal email saying you violated terms and conditions. But the creators do not know which terms and conditions were violated. Some YouTube creators may resort to complaining on Twitter to get a response from the company. While I think YouTube is partly vague because of some legal situation. I think having a transparent AI can help. YouTube can show creators why the situation is like this. YouTube may not know what happened due to the black-box nature of the algorithm.
Interpretable AI will not solve all of technologies problems. A lot of problems frankly is a lack of government regulation and oversight. As in many areas of technology, there are no ground rules. So the technology companies are going in blind. And people are upset about whatever the tech companies do. If the legal situation changed were YouTube can tell its creators why it violated its terms and service. That will be great. Instead of having a cat and mouse game. If government officials even knew what it was talking about when it came to technology. Right now I think the European Union has the best understanding. While I think some of its initiatives are flawed. In the USA the government is only now waking up to the fact they need to rein in big tech. But I'm not confident that the government has a good understanding of the technology there dealing with. You can see some of the viral videos of the original Mark Zuckerberg hearings. Where the congressmen were asking questions that lacked a basic understanding of what the internet and Facebook even is. Never mind how should the government deal with data. Or incentivise companies to have transparent AI.
[1] Tech companies already do this to fight this misinformation. But an Interpretable can make this process easier.
To Get Better, Do the Real thing
I'm not going to lie; I haven’t been spending much time working on a machine learning project. Due to university work. While that may be a valid reason. That still means my machine learning skills won't get better. So soon I should start making it a priority to start training some models.
Recently I watched a podcast with Lex Friedman and George Hotz. Hotz is a very eccentric figure, to say the least. But a very fascinating person. Which made the podcast very enjoyable. On the area of self-help advice. He said that he can’t give good advice. Especially for generic questions. In his own words “how do I become good at things?” Where he said, “just do [the thing] a lot”.
When he was asked how to be a better programmer. He just replied be programming for 20 years. He says many times if you want to learn a skill you have to do it. When talking about self-help he said those books tend to be useless. As the things that people want to hear. Not real stuff like work harder.
Please do the real thing
This reminds of an article by Scott Young one of my favourite bloggers. Titled “Do The Real Thing”. Which echoes the sentiment above. That to get good at something. You want to do the real thing. Time and time again. Substitutes don’t count. He gave the example of his language learning journey. That if he wanted to get better at speaking in the foreign language he was learning. Then he had to speak the foreign language to native speakers. Learning vocab or reading can help. But he still needed to do the activity.
Same things apply to improving my machine learning skills. Make as many models as you can. You cannot help but get better. As you are googling things left right and centre.
Picking up the general process of making a deep learning project along the way. Getting data, cleaning the data. Choosing a model. Training the model. Testing the model. Debugging the model. Then publishing the model. Will be learnt by doing the thing.
Machine learning skills I want to learn
This is why I want to start a new project. But I don’t know what to build for my deep learning project.
I liked the green tea vs oolong tea project. I thought that was very original. I enjoyed making it. Even after the many frustrations of getting the model to work. And I learnt how to use Pytorch. Which is something I will likely be using in a future project.
I may spend more time expanding the green tea vs oolong tea model. Like converting it into an object detection model. Or publishing it so the public can use it. With services like stream lit. Or a custom frontend made with flask. Or convert it into a mobile app. While those options look nice.
I want to try something new. So I want to try a new project. Recently I have been thinking of trying something simple. Like a cat vs dogs image classifier. The reason why I thinking to do this. Is because I want an excuse to try the new FastAI library. As they rebuilt it from the ground up with Pytorch. So it will be nice to see what changed. And getting used to trying fastai again.
Still on the horizon is GANs. I always found GANs. Very interesting. But each time I tried to implement them I have always failed. So I think my prerequisites are not there. So soon I will probably try making a GAN.
Also like I mentioned in many previous blog posts. We need to learn how to implement models to the wider public, not just keeping it in our notebooks. I haven't been following my own advice. So I want to spend time using things like stream lit. Or having an API frontend for one of my ML projects. The production phase of the ml pipeline I think is not taught enough in the ML community. So I want to stay true to my word. And start learning about the production itself. Like ML-Ops and a basic fusion of software engineering and machine learning.
Now that I'm thinking about it one of the best ways to learn those skills is working for a tech company. As you need to publish to the wider public. The model needs to be effective enough where users can get results. But I don’t have that luxury yet. My projects will have to count.
Reading helps but Intuition comes from action
Going back to the topic at hand. All these areas I want to learn. Will need to be learnt by doing them. Getting the first-hand experience, you develop an intuition on the topic. And can produce tangible things with that knowledge. Further cementing your skills. Just reading about it will give you a high-level view of the topic. Which is fine. Not every single topic you need to learn the ins and outs of. But the ones that deep understanding can help you push towards your goals. Then doing the boring work of doing the real thing is a must.
Image classifier for Oolong tea and Green tea
Developing the Dataset
In this project, I will be making an image classifier. My previous attempts a while ago I remember did not work. To change it up a bit, I will be using the Pytorch framework. Rather than TensorFlow. As this will be my first time using Pytorch. I will be taking a tutorial before I begin my project. The project is a classifier that spots the difference between bottled oolong tea and bottled green tea.
The tutorial I used was PyTorch's 60 min blitz. (It did take me more than 60 mins to complete though). After typing out the tutorial I got used to using Pytorch. So I started moving on the project. As this will be an image classifier. I needed to get a whole lot of images into my dataset. First stubbed upon a medium article. Which used a good scraper. But even after a few edits, it did not work.

So I moved to using Bing for image search. Bing has an image API you can use. Which makes it easier to collect images compared to google. I used this article from pyimagesearch. I had a few issues with the API in the beginning. As the endpoints that Microsoft gave me did not work for the tutorial. After looking around and a few edits I was able to get it working.

But looking at the image folder gave me this:

After looking through the code I noticed that the program did not produce new images. But changed images to “000000”. This was from not copying the final section of code from the blog post. Which updated a counter variable.

Now I got the tutorial code to work we can try my search terms. To create my dataset. First I started with green tea. So I used the term "bottle green tea". Which the program gave me these images:

Afterwards, I got oolong tea, by using the term “bottle oolong tea”.

Now I had personally go through the dataset myself. And delete any images that were not relevant to the class. The images I deleted looked like this:

This is because we want the classifier to work on bottled drinks. So leaves are not relevant. Regardless of how tasty they are.
They were a few blank images. Needless to say, there are not useful for the image classifier.


Even though this image has a few green tea bottles. It also has an oolong tea bottle so this will confuse the model. So it's better to simplify it to having only a few green tea bottles. Rather than a whole variety which is not part of a class.
After I did that with both datasets. I was ready to move on to creating the model. So went to Google Collab and imported Pytorch.
As the dataset has less than 200 images. I thought it will be a good idea to apply data augmentation. I first found this tutorial which used Pytorch transformations.
When applying the transformation, it fell into a few issues. One it did not plot correctly, nor did it recognize my images. But I was able to fix it

The issues stemmed from not slicing the dataset correctly. As ImageFolder(Pytorch helper function) returns a tuple not just a list of images.
Developing the model
After that, I started working on developing the model. I used the CNN used in the 60-minute blitz tutorial. One of the first errors I dealt with was data not going through the network properly.
shape '[-1, 400]' is invalid for input of size 179776
I was able to fix this issue by changing the kernel sizes to 2 x 2. And changed the feature maps to 64.
self.fc1 = nn.Linear(64 * 2 * 2, 120) x = x.view(-1, 64 * 2 * 2)Straight afterwards I fell into another error:
ValueError: Expected input batch_size (3025) to match target batch_size (4).
This was fixed by reshaping the x variable again.
x = x.view(-1, 64 * 55 * 55) By using this forum post.
Then another error 😩.
RuntimeError: size mismatch, m1: [4 x 193600], m2: [256 x 120] at /pytorch/aten/src/TH/generic/THTensorMath.cpp:41
This was fixed by changing the linear layer again.
self.fc1 = nn.Linear(64 * 55 * 55, 120) Damn, I did not know one dense layer can give me so many headaches.
After training. I needed to test the model. I did not make the test folder before making the model. (rookie mistake). I made it quickly afterwards by using the first 5 images of each class. This is a bad thing to do. This can contaminate the data. And lead to overfitting. But I needed to see if the model was working at the time.
I wanted to plot one of the images in a test folder. So I borrowed the code from the tutorial. This led to an error. But fixed it by changing the range to one. Instead of 5. This was because my model only has 2 labels. (tensor[0] and tensor[1]) Not 4.
When loaded the model. It threw me an error. But this was fixed by resizing the images in the test folder. After a few runs of the model, I noticed that it did not print the loss. So edited the code to do so.
if i % 10 == 0:
print('[%d, %d] loss: %.5f' %
(epoch + 1, i + 1, running_loss / 10))
running_loss = 0.0
As we can see the loss is very high.
When I tested the model on the test folder it gave me this:

Which means it’s at best guessing. I later found it was because it picked every image as green tea. With 5 images with a green tea label. This lead it to be right 50% of the time.
So this leads me to the world of model debugging. Trying to reduce the loss rate and improve accuracy.
Debugging the model
I started to get some progress of debugging my model when I found this medium article
The first point the writer said was to start with a simple problem that is known to work with your type of data. Even though I thought I was using a simple model designed to work with image data. As I was borrowing the model from the Pytorch tutorial. But it did not work. So opted for a simpler model shape. Which I found from a TensorFlow tutorial. Which only had 3 convolutional layers. And two dense layers. I had to change the final layer parameters as they were giving me errors. As it was designed for 10 targets in mind. Instead of 2. Afterwards, I fiddled around with the hyperparameters. With that, I was able to get the accuracy of the test images to 80% 😀.
Accuracy of the network on the 10 test images: 80 %108 
Testing the new model
As the test data set was contaminated because I used the images from the training dataset. I wanted to restructure the test data sets with new images. To make sure the accuracy was correct.
To restructure it I did it in the following style:

https://stackoverflow.com/a/60333941
While calling the test and train dataset separately.
train_dataset = ImageFolder(root='data/train')test_dataset = ImageFolder(root='data/test')
With the test images, I decided to use Google instead of Bing. As it gives different results. After that, I tested the model on the new test dataset.
Accuracy of the network on the 10 test images: 70 %107
As it was not a significant decrease in the model learnt something about green tea and oolong tea.
Using the code from the Pytorch tutorial I wanted to analyse it even further:
Accuracy of Green_tea_test : 80 %Accuracy of oolong_tea_test : 60 %
Plotting the predictions
While I like this. I want the program to tell me which images it got wrong. So, I went to work trying to do so. To do this, I stitched up the image data with the labels, in an independent list.
for i, t, p, in zip(img_list, truth_label, predicted_label):
one_merge_dict = {'image': i, 'truth_label': t, 'predicted_label': p}
merge_list.append(one_merge_dict)
print(merge_list)
On my first try I got this:

As we can see its very cluttered and shows all the images. To clear it out I removed unneeded text.

Now I can start separating the images from right to wrong.
I was able to do this by using a small if statement
Now the program correctly plots the images with the incorrect label. But the placement of the images is wrong. This is because it still uses the placement of the other correct images. But the If statement does not plot them.
I corrected it by changing the loop:

I wanted to get rid of the whitespace, so I decided to change the plotting of images.
ax = plt.subplot(1, 4, i + 1)
fig = plt.figure(figsize=(15,15))

Now I have an idea, what the model got wrong. The first sample the green tea does not have the traditional green design. So it’s understandable that is got it wrong. The second sample. Was oolong tea but misclassified it as green tea. My guess is the bottle as has a very light colour tone. Compared to the golden or orange tone oolong bottles in the training data. Then the third example, where the bottle has the traditional oolong design with an orange colour palette. But the model misclassified it with green tea. I guess that the leaf on the bottle affected the judgement of the model. Leading it to classify it as green tea.
Now I have finished the project. This is not to say that I may not come back to this project. As an addition to the implementation side could be made. Like having a mobile app that can detect oolong or green tea. With your phone's camera. Or a simple web app, that users can upload their bottled tea images. And the model can classify your image on the website.
Why learning how to use small datasets is useful for ML
Many times, you hear about a large tech company doing something awesome with ML. You think that’s great. You think how can I do the same. So you copy their open-source code. And try it for yourself. Then you notice the result is good but not amazing. Than you first thought. Then you spotted that you are training the model with less than 200 samples. But the tech company is using 1 million examples. So you conclude that’s why the tech company’s model performs well.
So this brings me the topic of the blog post. Most people who are doing ML need to get good at getting good results with small datasets. Unless you are working for a FANG company. You won't have millions of data points at your disposal. As we apply technology to different industries, we must deal with applying models when not much data is available. The lack of data can be because of any reason. For example, this could be that the industry does not have experience using deep learning. So, collecting data is a new process. Or maybe collecting data can be very expensive, due to extra tools or expertise involved. But I think we need to get used to the fact that we are not Google.
We do not have datacentres full of personal data. Most businesses have less than 50 employees. With the company dealing with a few thousand customers. To a few dozen depending on the business. Non-profits may not even have the resources to collect a lot of data. So just getting insights from the data we have. Is super useful. Compared to trying to working with a new cutting edge model. With bells and whistles. Remember your user only cares about the results. So you can use the simplest model. Heck, if a simple feed-forward neural network works then go ahead.
But we should not worry about having the resources of tech companies. But worry about what we can do with the resources we have now. A lot of gains in ML are simply done by throwing ungodly amounts of data at the model. And seeing what happens next. We need to do that with only less than 200 samples. Luckily, people have developed techniques that may help with this. Like image augmentation that edits photos. Which helps the model learn about the image in different orientations. So has a general idea of the object of the image. Regardless of any minor edits like size or direction. Soon we may have GANs, that help produce more data from a small dataset. Which means we can train a model with larger datasets. Thanks to generated data of GANs.
While reading about GPT-3 is fun. And very likely to lead to some very useful products. (Just check out product hunt). We are not going to have the opportunity to train a 10 billion parameter behemoth. Don’t get me wrong, we don’t need to train a large model from scratch to be useful. This is what fine-tuning is for. The people using GPT-3 are not training the model from scratch but using prompts to help prime the model to solve the problems it will be dealing with.
But I think we need to deal with the bread and butter issues that people want an AI to solve. Like a simple image classifier. Which may be useful for a small business which needs it to sort out different weights in its store. Or a simple time series analysis to forecast sales into the next season for the shop keeper. Models from Facebook and google that have 100 layers will not be helpful. And likely give you grey hairs by setting it up. Again, the whole goal is the solution to your customer’s problem. Not to split the atom.
Like a podcast, I heard a while ago. Deep learning is already powerful enough. We just need to get it into the hands of the right people. Hopefully, I can help with that process. To do that we need to be a pragmatist and deal with the restraints that most people have when applying ML to their projects. While I'm happy the researchers in OpenAI and the FANG companies take deep learning to its limits. I want to have on the ground experience of taking that knowledge and improving the world. (Yes, its sounds very hippy). But most people will not have the resources to spent millions of dollars on a cloud provider to train a model. People may have a budget of a few hundred or a few maybe a thousand. But not a few million. With rates of cloud computing, a budget like that should be more than enough. Especially dealing with small models with small datasets.
The boring work of implementing ML models
As I write blog posts of the potential for AI to help industries. Or some hype article in the media talking about how AI can help revolutionise the world or your favourite industry. We forget the day to day work needed to make that future into reality.
What should you do with the data?
Yes, having AI look at medical images is great and gives more accurate predictions than doctors. But how do you get that data? Medical data is hard to obtain for good reason. Patients medical history should not be passed around willy-nilly. As its very sensitive information. This is not just data about your music preferences. It's about their lives. After you get the data. How should you train the data? A simple 2D medical image may require a Convolutional neural network. The default for computer vision. How do you train the data? You will need labels. So, the computer knows what it's looking at. A person with expertise in the field (a doctor). Will need to help label the images. Depending on the goal of the model, the doctor will need to point out items in an image. (for object detection). Or just give the general category of the image. (image classifier). Now you have trained the model. And if a model is good. If the model is correct more often than doctors. Then you can think about how to move the model to production.
How do you make sure the model is safe for use?
Hospitals are known for some terrible bureaucracy and paperwork depending on your country. So how would you get this AI into the hands that need it the most? For example, should the doctor access the model via a web app? Then upload an image to the website. Or should it be a mobile app? Where the doctor can point his camera at his hospital computer and the app gives a result. Only talking to your prospective users will give you the answer. If the diagnosis is wrong, who comes under fire? The model or doctor. So, there are even ethical questions when it comes to some areas of using machine learning.
When Google added machine learning to its data centres. To help with energy usage. They added fail safes just in case the AI does something funky. Many times, humans had to do a final send-off of approval. When the AI changed something, the humans were always in the loop. So, depending on the scale and activity. Safety features may have to get built-in. Rather than just focusing on getting accuracy on your model. But tons of areas where machine learning will be used. Such safety features won’t be needed. It will likely speed up time extracting useful information from the company’s data. Like spreadsheets or text documents. The main issue is privacy. Because if they contain personal data of customers. Then ethics and regulations like GDPR get involved. But these are problems you will face even before touching the model.
What should you do with missing or inadequate data?
If the user decides to opt-out of giving data in certain areas. How should the company give model recommendations to the user? Maybe it will need to guess by using other data from the user. Or maybe, it bases guesses on other users similar to the original user. Or maybe just say to the user you can’t use the service unless you opt-in into giving certain data. I don’t know. I guess it will depend on the company and the service they are providing.
Let's say you want to use satellite data and/or remote sensing for your project. One major question you need to ask before starting your project. Is the spatial resolution enough for your image? If not, then you start to notice halfway through collecting your data. That it's not good enough. As you can’t zoom in enough to get features you want from the image. This affected me in one of my projects. So I was later forced to use screenshots from google earth. If the project has commercial value. Then it may make sense to buy higher resolution images. From places like Planet Labs that release high-quality satellites into space. Allowing for high-resolution images with daily or close to daily updates. These things that don’t get mentioned in media articles talking about “HoW RemTOe SeNing can HElp Your Business.” To get cool things to work, you will need to do boring things.
Sending the model to production
I didn't even get to the step by step problems of releasing your model to the public. Because if you are going to do so. You need to quickly learn how to use ML-ops and learn basic software engineering. An area I'm hoping to learn soon. Like I said in the medical example do you want to create a web-app or a mobile app. Maybe you want to create an API. As your users are going to be developers. But this side of machine learning is not talked about that much. After you release it, how will you update the model and even the app? Should users give user feedback to the model? Or are you going to do it personally by looking at user and error logs? Which cloud provider would you use to release your model? Would you go for the new serverless services or traditional server space? To improve the model would you collect user data separately. Then occasionally, train the model on new data? Or train as you go along. (Note: I don’t know if you can do this).
As I get more experience, I should be writing in more detail on how to solve these issues. Because I think this is an area that resources are lacking. Also, for my selfish reasons I want to share my work. Some apps allow you to interact with the model. This is something I want to do. Also, I could learn from the users of the app. So, something like that should be on the horizon. And if we want to have machine learning be useful. Then it's obvious they should be released in some type of way. An internal app. Or a public web app. Models are not useful when stuck in a notebook. They are useful when released for the wider world. And the model is being tested with reality.
Why The Best Model Can Be The Simplest
AI does not need to be in everything
Right now I’m making a project that should produce areas that have high risk of flooding in the future. To do that I had to create a model that would complete a time series analysis that would forecast into the future. Instead of using a deep learning model like LSTMs. I went with a tried and tested model for time series analysis called ARIMA. (this is because I was following a tutorial.) This made me think about how all the bells and whistles are not needed.
As long as you're solving the problem the tool your using does not matter. I think this is the problem that people with engineering backgrounds have. They fall in love with the tool. Not solving the problem. Don’t get me wrong I do this all the time. But I think it’s important to solve the problem first. Rather than having a tool and finding a problem to solve it with. Granted I do this a lot.
I have been doing a lot of this recently, as a bid to improve my machine learning skills. I have been finding problems that will require me to make models. So, there is a time and place for all this. One of the benefits of having a simple model. Is stuff are less likely to break down. As you have fewer dependencies and connections between different bits of your code. It makes it easier to maintain. As your not getting a headache trying to comb through your model. The more stuff you add, the harder it is to troubleshoot the model. For example, if your model is overfitting. And you're trying to fix it with 10 layers. It will be harder as you need to tweak the parameters of all the 10 layers. Compared to a simpler model with only 3 layers. Also, this will take fewer resources so if you're running the model on the local computer. Then your computer is less likely to kneel over. Which saves you from buying a new computer, which is great.
Making Useful Projects
From Seth Goldin, This is Marketing:
It doesn’t make any sense to make a key and then run around looking for a lock to open. The only productive solution is to find a lock and then fashion a key. It easier to make products and services for the customer you seek to serve than it is to find customers for your products and services.
While he was talking about making products. It relates to this blog post. As solving problems is making products and services even if we don’t call it that.
In my applied technology blog post. I talked about how people can make an effective solution using simple tools. The example I gave in the article was a radiologist that made an ML model to find fractures in X-rays. Using Google’s no-code machine learning tool. This shows we can create useful products with simple tools. I think we should not be too nerdy about tools. Granted being nerdy is great, but we should always be thinking about the end-user first and foremost.
I think lots of developers get stuck into the “build it they will come” mindset. I’m only recently shedding this mentality right now. Putting my focus on people’s needs and wants. Granted I still want to build cool things, but if we want people to use our products then they need to be useful. The reason why machine learning is popular now, is that it helps solve problems that we could not do before. And we have the elements to make it more effective. Like powerful computing power and lots and I mean lots of data. This helped deep learning go mainstream.
I think I mentioned this in another blog post, but this is why I choose projects that I could see a person using. Not working out handwritten numbers from the MNIST dataset. The whole point of having tools is to allow us to solve a problem that we couldn’t without the tool. We have a hammer to punch in nails which we couldn’t do before. We have paddles to help us travel by boat quicker. And we have a computer to help us compute things ridiculously fast. So we should not get distracted by the next shiny toy (tool). This does not mean you should not change and stick the tools you already know. If that was the case, we still will be using sticks and rocks.
The Tool does not matter, it’s the solution that matters
From Patrick McKenzie (Patio11)
Software solves business problems. Software often solves business problems despite being soul-crushingly boring and of minimal technical complexity.
…
It does not matter to the company that the reporting form is the world’s simplest CRUD app, it only matters that it either saves the company costs or generates additional revenue.
Even when companies are using advanced technology and techniques. Sometimes the goal is still very simple. Netflix has a great recommendation system, so you watch more movies. Facebook has PhDs in Psychology and Artificial intelligence so you can spend more time on Facebook. And look at more ads. Google has crawled the entire internet. So when you use search you get the information you want.
Again, it all comes back to the end-user. I'm a Nerd, so all this stuff interests me, I can spend all day tinkering with new technology. But we must remember that when building something it should help somebody else. It does not matter how small the audience is. Many people say the audience can just be yourself. This is helpful because if its useful for one person then is probably useful to other people.
While I'm writing this, a lot of content here can be applied to myself. Which is partly why I’m writing this blog post. To say, don’t make things complicated if they don’t need to be. Don’t create a rocket ship when you can just get a boat. Don’t get me wrong. Building things is fun. Which is why I have a hobby like this. But it's important not to get too distracted.